ELK 구축 부터 log 파싱, 적재 까지 (with SpringBoot)
구축
- https://github.com/deviantony/docker-elk
- docker-compose.yml 파일 수정 후
docker-compose up -d
메모리 세팅
- 기본 설정에는 JVM Heap이 256m으로 작게 설정되어 있어서 이를 늘려주어야 함.
- docker-compose.yml 의
ES_JAVA_OPTS, LS_JAVA_OPTS설정 (또는 docker 컨테이너 실행 환경 전체에서 제한) - 너무 작게 세팅되어 있는 상태로 운영하면 ES나 Logstash 인스턴스가 java.lang.OutOfMemoryError: Java heap space 뜨면서 죽어버릴 수 있음.
- 그렇다고 너무 넉넉하게 줘서 시스템 전체가 메모리 부족에 시달리면 불필요한 GC, thrashing이 발생해서 전체 시스템이 더 느려짐. (다 같이 느려져서 결과적으로는 더 느려지는 효과) 적절한 설정이 중요.
- 그렇다면 메모리를 얼마나 줘야 하나?
- 옵션을 안주면 알아서 적절한 수준으로 설정하게 되는데, 대부분 환경에서는 이렇게 자동으로 설정하도록 놔두는 것을 추천하고 있다.
- 그래서 따로 옵션 주지 않고, 그냥 docker나 wsl 전체에서 메모리 한도를 두는 방법도 좋다.
- https://www.elastic.co/guide/en/logstash/current/jvm-settings.html
- LS : 4 ~ 8 정도로 하라고 나와 있지만 1g 정도로도 잘 돌아간다.
- https://www.elastic.co/guide/en/elasticsearch/reference/current/advanced-configuration.html#set-jvm-heap-size
- ES : 기본 옵션은 인식 가능한 메모리의 50%인데, fs cache를 사용하기 위해서는 이 정도가 적당하다.
- 4G 정도로도 잘 돌아간다.
- 메모리를 많이 주면 internal cache를, 적게 주면 fs cache를 더 높은 비율로 사용한다.
- 옵션을 안주면 알아서 적절한 수준으로 설정하게 되는데, 대부분 환경에서는 이렇게 자동으로 설정하도록 놔두는 것을 추천하고 있다.
- 설정 후 Management - Stack Monitoring 항목 확인해볼 것. 참고로, JVM 자체도 메모리가 필요하므로, It’s normal for Elasticsearch to use more memory than the limit configured with the Xmx setting.
계정 관련 설정
- 무료이므로 나와 있는 대로 진행하면 됨.
- Initial setup 부분 참고하여 PW 생성 및 변경 해 주고, yml conf 파일에 변경된 PW 적용 한 다음, 변경된 PW로 elastic 계정 키바나 로그인 하고, Management - Users 에서 새 superuser 계정 만들어서 이를 사용하면 된다.
Kibana HTTPS 설정
- https://www.elastic.co/guide/en/elasticsearch/reference/7.14/security-basic-setup-https.html#encrypt-kibana-browser
- 앞단에 nginx가 있다면 SSL은 거기서 통합으로 처리하는 방법을 사용해도 좋다.NGINX
- 인증서 인증은 Let’s Encrypt & Certbot 으로인증서 발급 & 인증 받기
- 인증서는 호스트 머신에 두고 docker-compose.yml에 mount 추가.
- 컨테이너에 넣고 commit 하는 것 보다 mount가 나아보임.
- 수정 후
docker-compose up -d
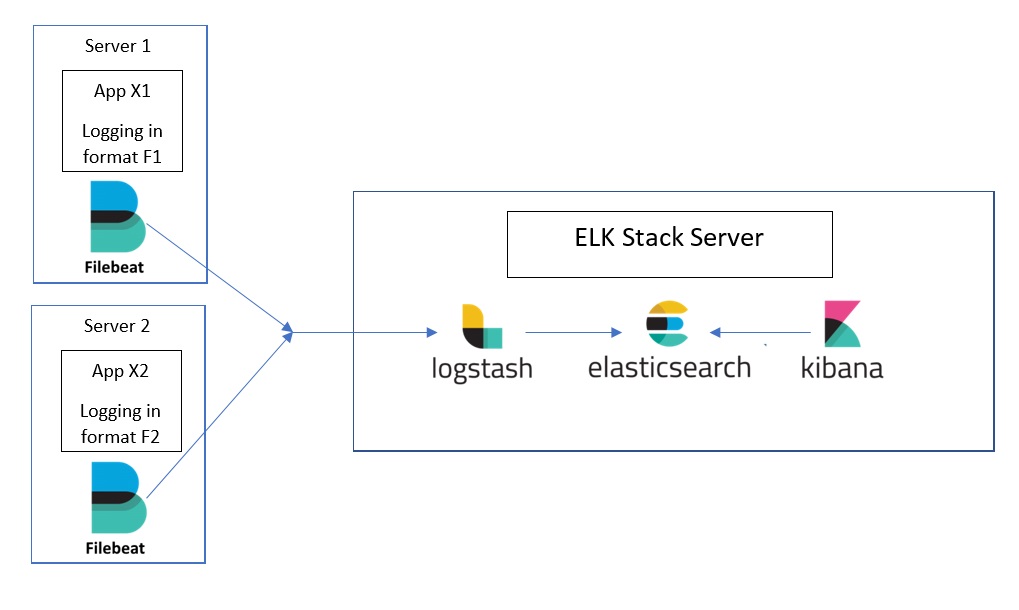
log 수집 방법 및 서버 아키텍쳐
일반적인 상황에서는, Filebeat + ELK
1
2
3
4
// 모두 가능하지만, 첫 번째 설정이 일반적임.
file - Filebeat - Logstash - ES
file - Logstash - ES
file - Filebeat - ES
- Filebeat는 데이터를 수집하여 전송하는 역할
- 서버에 Filebeat 설치하고 설정해주면, 지정한 로그 파일 모니터링하고 실시간으로 변경 체크해서 이벤트 수집하고 ES로 전송 (tail -f와 유사하게 동작함)
- 파일 내용과 offset을 전송함.
- 어떤 file, line을 logstash로 보낼지. file & line 단위 include/exclude 설정 가능
- Logstash는 데이터를 읽어와 가공하는 역할. 가공 후 ES로 전송.
- 가공(파일내용 파싱)은 logstash에서 하도록 설정함.
- 필드 단위 설정
- e.g., logstash에서 라인을 grok로 파싱해서 필드 별로 식별하고, 불필요한 필드는 제거한 다음 ES로 전송
- Filebeat 없이 Logstash가 직접 수집 할 수도 있다.
- 가공(파일내용 파싱)은 logstash에서 하도록 설정함.
Filebeat를 쓰는데 Kafka를 추가로 사용하는 경우?
1
Filebeat - Logstash Shipper - Kafka - Logstash Indexer - ES
filebeat <> logstash 사이에 backpressure가 있기 때문에 굳이 kafka를 둘 필요는 없다.
[!tip] Filebeat는 Logstash나 Elasticsearch로 데이터를 전송할 때 backpressure-sensitive 프로토콜을 이용하여 더 많은 데이터 볼륨을 처리합니다. Logstash가 데이터 처리로 인해 정체된 경우 Filebeat가 읽기 속도를 늦추며. 정체가 해결되면 Filebeat가 원래 속도를 되찾아 수집을 계속합니다.
file - logstash로 바로 읽을 수 있으면, 굳이 왜 Filebeat를 쓰나?
아래와 같이 설정하면 Filebeat 없이, logstash가 바로 file을 읽어들일 수 있다.
1
2
3
4
5
6
7
8
9
10
input {
file {
path => /tmp/spring.log
codec => multiline {
pattern => "^(%{TIMESTAMP_ISO8601})" // {이 부분을 logback log prefix와 동일하게 설정}
negate => true
what => "previous"
}
}
}
그럼에도 filebeat를 쓰는 이유는, 아래 내용과 아키텍처 그림을 참고하면 이해가 된다.
Logstash가 데이터 수집기로서의 역할을 훌륭하게 해 내고 있지만 너무 다양한 기능 때문에 프로그램의 부피가 컸고 실행하는 데에 꽤 많은 자원을 필요로 했습니다. Elasticsearch 클러스터로의 대용량 데이터 전송은 보통 하나의 소스가 아닌 다양한 시스템들로부터 수집을 하였기에 그 모든 단말 시스템에 Logstash를 설치하는 것은 적지 않은 부담이었습니다. 그래서 Logstash팀은 단말 시스템으로 부터 데이터를 수집하고 필터기능 없이 가볍게 Elasticsearch 또는 Logstash로 데이터를 전송하는…
Filebeat 없이 네트워크를 통해 logstash로 바로 쏘는 구조 : pros and cons
1
app(using network) - Logstash - ES
[!info] One big disadvantage of traditional plain text log format is that it is hard to handle multiline string, stacktrace, formatted MDCs etc.
- Filebeat에서 멀티라인을 처리하려면, multiline.pattern을 따로 정의해주어야 해서 설정이 약간 까다롭다는 단점이 있다.
- 아래 예제 처럼 로그 형식이 한 가지로 일정하다면 괜찮지만, 다양하다면? 정규식도 복잡해지고 수용이 안된다.
- Keep things simple and let the application just write the logs to disk. 이기는 하지만, 설정으로 수용이 안되면 어쩔 수 없다.
- json으로 가공하여 로깅하면 멀티라인을 신경쓰지 않아도 되므로, SpringBoot log를 ES에 적재할 때는 별도의 logback appender를 사용하여 json string을 (추가적인 log 파일로 로깅하거나, 네트워크로 바로 쏘도록) 하는 경우가 있다.
- 보통 둘 중에서는 후자를 많이 씀.
- 전자의 단점 : txt log가 있는데 별도 json log를 또 만드는 것이 지저분하다.
- 후자의 단점 : 이렇게 file로부터 적재하지 않고 network로 바로 쏘게 되면…
- elk 다운타임 동안 로그가 유실된다. (큰 단점) network로 바로 쏘는 방법도 backlog queue를 쓰긴 하지만, 결국 다 차면 lost 발생한다.
- 스레드들이 다운된 elk의 http 응답을 timeout 시간 동안 기다리면서 스레드가 낭비된다. 심하면 스레드풀 고갈로 인한 서비스 지연이나 장애로 이어질 수 있다. (io thread pool 분리, 비동기 전송, timeout 시간 설정 신경써주어야만 한다.)
- 이러한 단점 때문에, 보통은 로그 형식이 한 가지로 일정하므로, filebeat에 일반 line으로 로깅하고 multiline 처리하는 방법이 군더더기 없이 깔끔하여 난 이 방법을 선호함.
- 별도의 json log 파일 생성하지 않으므로 깔끔하고,
- elk 장애가 나더라도, 정상화 후 file에서 읽었던 곳 부터 적재해 나가면 되므로 통계 유실 가능성 낮음.
- 그럼에도 불구하고 네트워크로 바로 쏘도록 하려면, logback 사용 중인 경우 xml에 appender 하나 추가하는 식으로 간단히 수집 가능함.
- https://techblog.woowahan.com/2659/
- https://github.com/internetitem/logback-elasticsearch-appender
- appender 마다 구현이 다를 수 있지만 보통 일정 시간 동안 log를 모았다가 주기적 scheduling을 통해 bulk로 한꺼번에 보낸다. (보내고-받고 반복 하면 RTT가 낭비되니까)
Network로 바로 쏠 때 Kafka를 추가로 사용하는 경우
1
app(using network) - kafka - logstash - Es
- filebeat를 쓰지 않고 network로 바로 쏘는 경우
- 서버가 너무 많아 일일히 filebeat를 설치하고 관리하기 귀찮은 경우 app에서 바로 쏘도록 구성하는 경우도 보인다.
- app에서 직접 logstash로 바로 쏘는 경우 [burst, logstash down] 시 유실 가능성 있으므로 kafka를 버퍼로 둔다.
- 트래픽 burst가 심하지 않은 경우 굳이 kafka 안두고 logstash의 persistent queue (기본 비활성화) 만으로도 충분해보이나… logstash down에 대한 대비책으로는 미흡하여, 이런 부분 까지 고려한다면 kafka를 두어야 한다.
- kafka를 버퍼로 두어도, filebeat 사용하는 것 보다 유실 가능성이 크다.app<>kafka 사이에 network 장애 있는 경우.
- 그래서 filebeat 사용하는 것이 더 안정적으로 보인다.
- https://www.elastic.co/kr/blog/just-enough-kafka-for-the-elastic-stack-part1
- 공식 docs 내용이 좋다. Kafka 추가를 고민하고 있다면 꼭 읽어보는 것이 좋을 듯.
conf 설정
Filebeat 설정 (springboot log)
- Springboot log는 filebeat에서 지원하는 module이 없어 직접 설정해주어야 한다.
- One big disadvantage of traditional plain text log format is that it is hard to handle multiline string, stacktrace, formatted MDCs etc.
- stacktrace 등 멀티라인 로그 처리를 위해서는 별도 설정 넣어주어야 한다.
- logstash 설정
input { beats }에서는 multiline codec을 사용하지 못한다. 즉, filebeat를 사용하는 경우 멀티라인 처리는 filebeat에서 해서 넘겨줘야 한다.
[!info] 구버전 filebeat에서는
type: log를, 최근 버전 filebeat에서는type: filestream을 사용한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
filebeat.inputs:
- type: log
enabled: true
paths:
- /home/ec2-user/logs/spring*.log
#### Multiline options : stacktrace 같은 멀티라인 로그 처리를 위해
## The regexp Pattern that has to be matched.
multiline.pattern: {이 부분을 logback log prefix와 동일하게 설정}
## 예시: ^[0-9]{4}-[0-9]{2}-[0-9]{2}[ T][0-9]{2}:[0-9]{2}:[0-9]{2}.[0-9]{3}[[:space:]]+(TRACE|DEBUG|INFO|WARN|ERROR)
## true이면 pattern과 일치하는 로그를 새 로그의 시작으로 본다.
multiline.negate: true
## pattern 이후에 다른 라인이 붙을지, 이전에 붙을지를 결정한다.
multiline.match: after
## 상세 설명은<https://www.elastic.co/guide/en/beats/filebeat/current/multiline-examples.html>참고
1
2
3
4
5
6
7
8
9
10
11
12
filebeat.inputs:
- type: filestream
id: my-filestream-id
enabled: true
paths:
- /home/ec2-user/logs/spring*.log
parsers:
- multiline:
type: pattern
pattern: '^[0-9]{4}-[0-9]{2}-[0-9]{2}[ T][0-9]{2}:[0-9]{2}:[0-9]{2}.[0-9]{3}[[:space:]]+(TRACE|DEBUG|INFO|WARN|ERROR)'
negate: true
match: after
- regex pattern 설정하는 부분이 약간 까다로울 수 있다.
- optional fields는 inputs 마다 각각 설정도 가능하고, general 설정도 가능하다.
- hostname 로깅은?fields? name? tags? 어떤 것을 사용하면 되나?
- name이 그런 목적으로 존재하는 필드다. If this option is empty, the hostname of the server is used. The name is included as the
agent.namefield in each published transaction. You can use the name to group all transactions sent by a single Beat. - 하지만 서버를 이전한다거나 해서 hostname이 변경 될 수 있으므로 직접 설정해서 사용하는 것을 권장.
- host.* 필드도 있는데,add_host_metadata processor가 add&overwrite하는 필드. 필요하지 않다면 processors에서 주석처리하여 제거해준다.
- 기타 필요없는 필드가 있다면 아예 보내지 않도록drop_fields (예제 )하거나, logstash에서 받을 때 remove_field 해준다.
- name이 그런 목적으로 존재하는 필드다. If this option is empty, the hostname of the server is used. The name is included as the
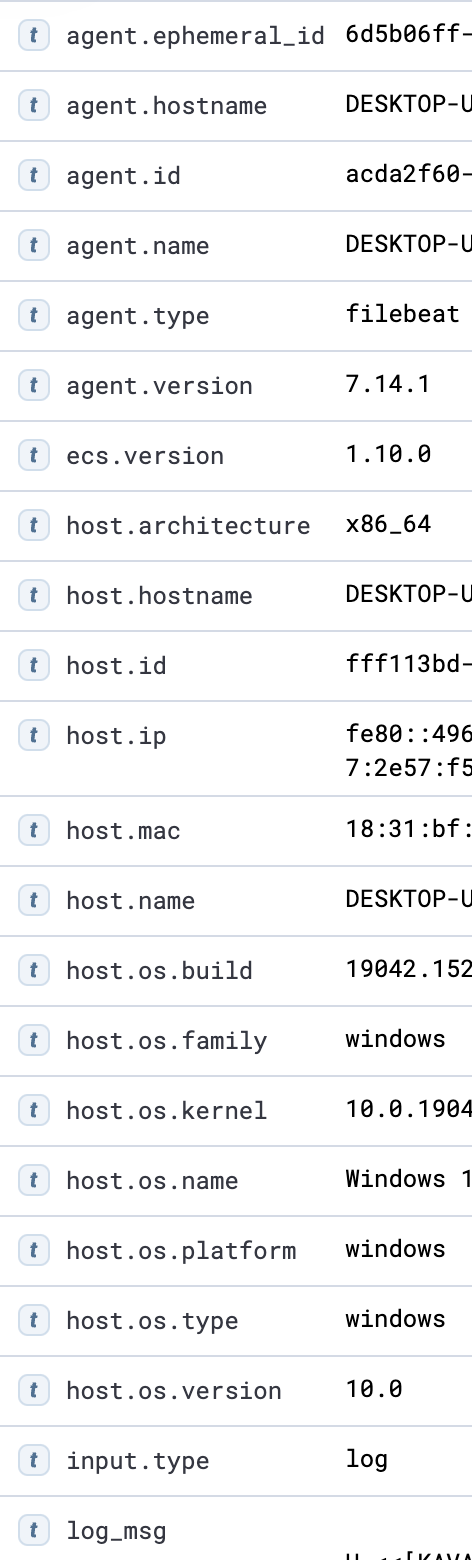 filebeat는
filebeat는 agent.* host.*을 보내는게 기본 옵션. 기본 포함 필드는 버전 따라 다를 수 있음.
filebeat - logstash SSL 설정
- 특히, host 정보를 http로 보내는 경우 호스트머신 버전이 공개 될 수 있음 (SSL 적용 가이드, 공식)
- CA 인증서를 비트에 등록하고 그래야해서… 기존에 쓰던 인증서가 있어도 그냥 가이드 보고 ca부터 인증서까지 새로 만료일자 넉넉하게 해서 하나 만드는게 속편함.
- 기존에 쓰던 인증서를 사용하려면 pkcs8 변환해야되고 ca 인증서 다운받아야 하고 갱신 신경써야 하고 이래저래 귀찮다.
[!warning] ssl 세팅 후 filebeat.yml에 logstash 서버 명시 할 때, 인증서와 결합된 domain name이 아니라 ip 입력해도 당장은 잘 동작하지만 권장하지 않는다. 나중에 서버 ip가 변경되었는데 domain과 연결된 ip는 변경하지 않는 경우, filebeat.yml의 서버 ip를 새로운 ip로 변경해도, 서버의 ip와 인증서의 domain name(-> ip)와 일치하지 않기 때문에 filebeat가 인증서를 무시하는 것 같다.
== https가 적용되지 않아 logstash와 handshake가 불가능하다.
Spring logback preset 로그 포맷에 맞춘 logstash 설정
- https://github.com/spring-projects/spring-boot/tree/main/spring-boot-project/spring-boot/src/main/resources/org/springframework/boot/logging/logback
- https://www.elastic.co/guide/en/logstash/current/plugins-outputs-elasticsearch.html index 관련 설정 공식 docs
- https://www.elastic.co/guide/en/logstash/current/event-dependent-configuration.html#logstash-config-field-references grok 구문 관련 docs
- https://www.elastic.co/guide/en/logstash/current/plugins-filters-json.html json filter 관련 docs
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
input {
beats {
port => 5044
}
tcp {
port => 5000
}
}
## Add your filters / logstash plugins configuration here
filter {
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:[loginfo][date]}\s+%{LOGLEVEL:[loginfo][level]} %{POSINT:[loginfo][pid]} --- \[\s*%{DATA:[loginfo][thread]}\] %{DATA:[loginfo][class]}\s+: %{GREEDYDATA:[loginfo][message]}" }
}
date {
match => ["[loginfo][date]", "yyyy-MM-dd HH:mm:ss.SSS"]
target => "@timestamp" // 명시하지 않으면 기본값 @timestamp 이지만 명시해주는 편이 좋아보임
timezone => "Asia/Seoul" // (필수) timezone을 명시하지 않으면 시간이 이상하게 파싱될 수 있음
}
mutate {
remove_field => ["host", "message", "[agent][type]", "[agent][ephemeral_id]", "[agent][version]"]
}
}
output {
elasticsearch {
hosts => "elasticsearch:9200"
user => "elastic"
password => "yourpassword"
ecs_compatibility => disabled
index => 'logstash-%{+YYYY.MM}'
}
}
 grok 필드 파싱 결과
grok 필드 파싱 결과
index 설계
- (중요) ES에서 필드를 인식할 때는 타입까지 인식한다. 그래서 한 인덱스 안에서 필드 네임 a는 타입이 항상 같도록 구성해야 한다. (한 필드 네임의 타입이 다양한 경우 하단에 기술한 에러를 마주할 수 있음)
- visualize 시, 한 index 내의 항목들을 조합해서 visualize하게 된다.
서로 다른 index 사이의 항목들을 동시에 조회해 visualize는 안되는 것으로 보임.(lens, TSVB, timelion 사용하면 가능하다link ) - 로깅용 객체를 따로 두는 것도 고려해볼만 함.
결론 ) 같은 객체, 같은 통계를 공유하면 같은 index로 구성한다.
log message에서 index || logtype을 식별하여 별도 index로 적재하는 logstash 설정
- 기타 설정은 위와 같음
- [loginfo][type]이 없는 경우 logstash index로 적재하며 json 파싱 없이 문자열 그대로 log_msg 필드에 매핑
- [loginfo][type]이 있는 경우 json 파싱
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
/* 기타 설정은 위와 같음 */
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:[loginfo][date]}\s+%{LOGLEVEL:[loginfo][level]} %{POSINT:[loginfo][pid]} --- \[\s*%{DATA:[loginfo][thread]}\] %{DATA:[loginfo][class]}\s+: (\#_\[%{DATA:[loginfo][type]}\]_\#)?%{GREEDYDATA:[@metadata][body]}" }
}
if ![loginfo][type] {
mutate {
add_field => { "[@metadata][target_index]" => "logstash" }
add_field => { "log_msg" => "%{[@metadata][body]}" }
}
} else {
mutate {
add_field => { "[@metadata][target_index]" => "%{[loginfo][type]}" }
}
json {
source => "[@metadata][body]"
}
}
output {
elasticsearch {
index => '%{[@metadata][target_index]}-%{+YYYY.MM}'
...
1
2
3
4
fun Logger.infoEs(index: String, obj: Any) {
val jsonStr = ES_OBJECT_MAPPER.writeValueAsString(mapOf(obj::class.simpleName to obj))
info("#_[$index]_#$jsonStr")
}
Kibana에서 List 타입 데이터 적재 시 출력 방식
1
2
3
4
5
6
7
8
9
10
11
12
13
[
{
"f1": "qwer",
"f2": 1234,
"f3": [1, 2, 3]
},
{
"f1": "qwer",
"f2": 1234,
"f3": [1, 2, 3]
},
...
]

- f2와 f3는 숫자 타입이므로 visualize 에서 sum 등이 가능
- f3같은
[[1, 2, 3], [1, 2, 3]]은 1, 2, 3, 1, 2, … 가 된다는 점을 주의해야 함 - ES는 완벽한 BigDecimal 처리가 없다는 것도 참고. scaled_float가 있지만 무손실은 아니다.
기타
“error”=>{“type”=>”illegal_argument_exception”, “reason”=>”mapper [필드명] cannot be changed from type [long] to [float]”} 발생하는 경우
- 이게 왜 발생하는거냐면, index template에 정의되어 있지 않은 index pattern이 들어오는 경우, 해당 index의 필드 및 타입을 식별하기 위해서 ES는 기본적으로 Dynamic mapping을 사용함
- Dynamic mapping을 사용하면 최초 요청 시 필드의 값이 곧 그 필드의 타입이 됨. (1 -> long, 0.1 -> float)
- 참고로 해당 index가 필드를 어떻게 매핑하고 있는지는 Index Management - Mapping 메뉴에 나옴
- 최초 요청 시 필드 값이 1이어서 해당 필드 타입은 long이 되었는데, 그 필드에 0.1이 들어오면, long은 float로 변환 불가능하기 때문에 에러가 발생함.
- 이를 해결하려면?
- 최초 요청 시 0.1이 들어오면서 float가 될 때 까지 인덱스를 삭제하고 계속 재시도 하는 방법이 있고,
- index template을 정의하는 방법이 있음! (권장)
- index template을 정의하는 것이 귀찮을 수 있는데, 오류가 나는 필드만 명시하고 나머지는 Dynamic mapping에 맡겨도 되기 때문에 전혀 문제될 것이 없음.
Kibana에서 Alerts 보내기 위한 설정
- alert 기능 사용하려면 api key 생성 할 수 있어야 하는데, 기본 비활성화 되어 있으므로 설정 필요
- elasticsearch.yml에 xpack.security.authc.api_key.enabled: true 설정 추가
- 참고) Additional look-back time은 대상건 누락 방지를 위해 설정해주는 것이 좋다. 중복해서 잡힌 건은 알아서 무시해주기 때문에 중복 걱정은 안해도 된다. (docs )
- Alert 생성 및 집계 까지는 되는데, 실제로 알림을 받기 위해 WebHook이나 메일 같은 Connector를 등록하려면 Gold license(유료)가 필요하다.
- 무료로 WebHook을 사용해서 알림을 받는 방법은 2가지가 있는 것 같은데…
- Open Distro Kibana Plugin 과 호환되는 마지막 Kibana 버전(7.10.2)로 downgrade.
- https://guide-gov.ncloud-docs.com/docs/ses-use-dashboardsDashboard 모듈을 Kibana 말고 OpenSearch를 사용하면 무료로 가능.
OpenSearch
이제 ELK 쓸 필요 없이 OpenSearch 쓰면 되지 않을까?
- OpenSearch란?
- AWS 측에서 ELK를 SaaS 형태로 제공 하기 위해 ES 7.10 버전을 fork 떠서 유지보수 하고 있는 오픈소스 프로젝트다. AWS에서 관리하는 프로젝트라 유지보수 가 잘 되고 있는 듯.
- OpenSearch is a fork of open source Elasticsearch 7.10
- OpenSearch Dashboards (derived from Kibana 7.10.2)
- OpenSearch Dashboard 도 그렇고 전반적으로 ES, Kibana와 거의 유사해서 그냥 오픈소스이고 기능도 많은 OpenSearch 쓰는게 좋아보임.
- ES 측에서는 엄청 싫어하는듯. 성능 별로라고 깜…