(마틴파울러) Layering 관련 글 모음
https://martinfowler.com/bliki/PresentationDomainDataLayering.html
layer를 나누는 것의 장점
1. 관심 분리 (를 통해 작업 대상 layer에 집중 가능)
마틴 파울러는 layer를 나누는 것의 최고 장점은, 작업 대상이 되는 layer에만 집중할 수 있도록 해준다는 점이라고 얘기하고 있다.
It’s biggest advantage (for me) is that it allows me to reduce the scope of my attention by allowing me to think about the three topics relatively independently.
When I’m working on domain logic code I can mostly ignore the UI and treat any interaction with data sources as an abstract set of functions that give me the data I need and update it as I wish.
When I’m working on the data access layer I focus on the details of wrangling the data into the form required by my interface.
When I’m working on the presentation I can focus on the UI behavior, treating any data to display or update as magically appearing by function calls. By separating these elements I narrow the scope of my thinking in each piece, which makes it easier for me to follow what I need to do.
하지만 실제로 한 layer의 변화는 다른 layer의 변화를 초래하는 경우가 대다수다.
그럼에도 불구하고 layer가 나뉘어져 있는 것이 집중하기에 더 낫다.
I might build the data and domain layers off my initial understanding of the UX, but when refining the UX I need to change the domain which necessitates a change to the data layer. But even with that kind of cross-layer iteration, I find it easier to focus on one layer at a time as I make changes. It’s similar to the switching of thinking modes you get with refactoring’s two hats.
관심 분리는 클래스 수준의 의존성 분리와 모듈화에서도 얻을 수 있는 장점이지만, layer를 나누는 것은 보다 더 거대한 범위에서 각 layer에 대한 책임을 더욱 엄격히 제한 할 수 있으므로 거시적인 관심 분리에 도움이 된다.
예를 들어, ‘어떻게 표현할지는 비즈니스와 완전히 분리된 또 다른 영역으로 구분해서 생각하는 것이 좋다.’ 이 개념이 매우 중요하다.
2. layer를 나누면서 모듈화 하게 되므로, 모듈 갈아끼우기 가능.
- 각 layer가 자신의 세부사항을 몰라도 상관 없도록, 잘 추상화해서 제공하고 있다면 각기 다른 계층끼리 부품을 갈아끼우듯 변경할 수 있다.
3. layer를 나누면 그 만큼 테스트가 쉬워진다.
- 컴포넌트들의 의존 계층 관계를 깔끔하게 유지할 수 있으니 상대적으로 테스트가 쉬워진다.
- 예를 들어 data source에 대한 mocking이 필요하다면 persistence layer를 mocking
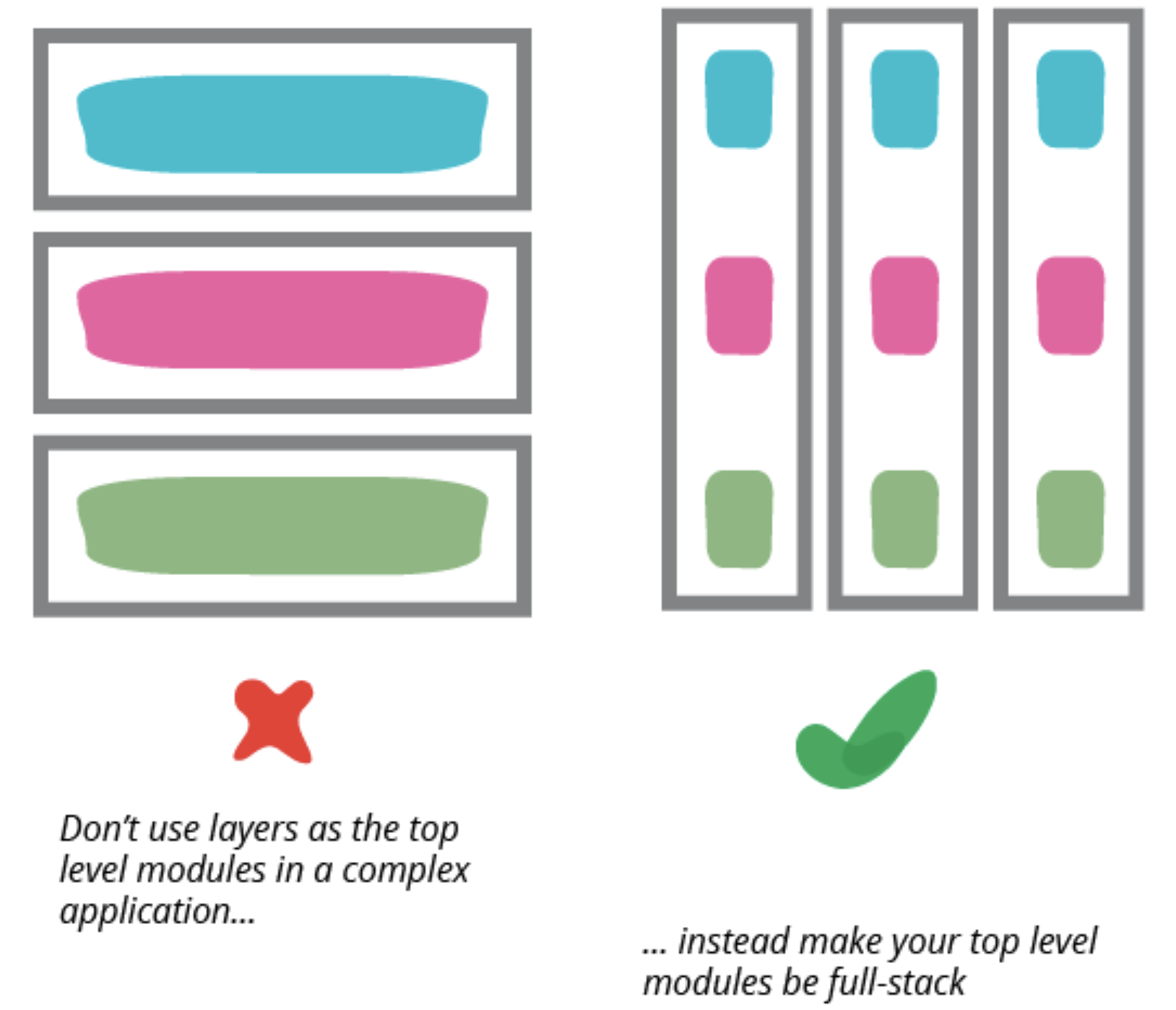
👍도메인을 최우선으로 나누고, 그 안에서 각자의 presentation-domain-data layering을 추구하자.
presentation-domain-data 구분 방식을 가로로 적용하는 것은, 소규모 시스템에서는 괜찮지만 대규모 시스템에서는 좋지 않다. 도메인을 최우선으로 나누고, 그 안에서 각자의 presentation-domain-data layering을 추구하자.
https://martinfowler.com/eaaCatalog/serviceLayer.html
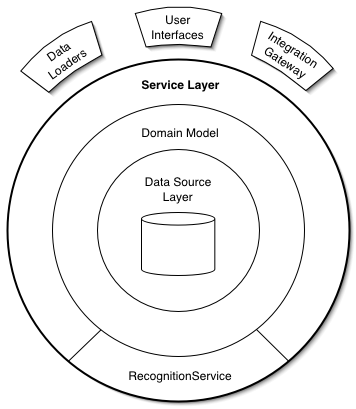 P of EAA: Service Layer
P of EAA: Service Layer
- 이 그림은 마치 Domain Model에서만 Data Source에 접근해야 될 것 처럼 표현되어 오해의 소지가 있을 것 같다.
기타 문서
- https://martinfowler.com/eaaDev/uiArchs.html- MVC, MVP 실제 사례와 diagram, code
- https://martinfowler.com/eaaDev/SeparatedPresentation.html- presentation layer 분리 실전 예제
- https://martinfowler.com/bliki/PresentationDomainSeparation.html- 원론적인 얘기
- https://martinfowler.com/bliki/LayeringPrinciples.html- layering 디자인 원칙에 대한 투표 결과. 찬반 결과가 항상 정답을 가리키지는 않지만 고민 될 때 도움이 될 수는 있다.
개인 의견
마틴파울러 글은 (거의 항상) 좋은 내용이고 평소에 하고 있던 고민에 대한 실마리가 되며 충분히 공감이 간다.
그러나 이를 시스템에 적용하려고 시도 할 때 마다, 무언가 디테일한 부분에서 약간씩 안맞는 부분이 생기는 것을 경험했다.
- specific한 설계는 각자가 처한 상황에 따라 다를 수 밖에 없기 때문에, 이런 설계에 대한 가이드를 세부적인 부분까지 너무 타이트하게 지킬 필요는 없다.
- 세부적인 내용(예를 들어, 여기서는 layering)은 각 시스템이나 비즈니스에 맞게 추가하거나, 빼는 등 취사선택하여 적용해야 한다. (마틴 파울러의 글은 대체로 제네럴한 컨셉에 대해 얘기하고 있으므로 모든 아키텍쳐와 모든 상황에 1:1로 fit하게 대응되지 않을 수 있다.)
- 하지만 본질에 대해서 제대로 이해하고 좋은 컨셉을 러프하게나마 설계에 적용하는 것은 놓치지 말아야 한다.
게다가, 마틴파울러는 이렇게 얘기하고 있다.
indeed even the more fundamental principle of co-locating data and behavior should sometimes be dropped in favor of other concerns - such as layering. Good design is all about trade-offs , and co-locating data and behavior is just one factor to bear in mind. …
A good rule of thumb is that things that change together should be together.