Spring Batch Multi-threaded Step 사용 시 chunk 구성에 대한 오해
개요
Spring Batch에서는 다양한 병렬 처리 방식을 지원하고 있습니다.
- AsyncItemProcessor / AsyncItemWriter
- Multi-threaded Step
- Parallel Steps
- Externalizing Batch Process Execution
이 중 Multi-threaded Step 방식에 대해 간단히 설명하고, chunk 구성 관점에서 제가 잘못 이해하고 있었던 부분 에 대해 얘기하려 합니다.
Multi-threaded Step 방식의 병렬 처리
Multi-threaded Step 방식은 step build 시 .taskExecutor()를 붙여주면, 한 Step 내에서 chunk 단위로 병렬 처리되는 방식입니다.
- 기존 코드에서 큰 변경 없이 사용이 간단하고
- 각 thread가 chunk 단위로 작업을 처리 (직관적)
때문에 자주 보이는 코드인데요.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
@Bean(STEP_NAME)
public Step step() {
return stepBuilderFactory.get(STEP_NAME)
.<A, B>chunk(CHUNK_SIZE) // CHUNK_SIZE = 10
.reader(reader()) // setPageSize(10)
.processor(processor())
.writer(writer())
.taskExecutor(
ThreadPoolTaskExecutor().apply {
corePoolSize = 3
maxPoolSize = 3
setThreadNamePrefix("batch-thread-")
initialize()
}
)
.build();
}
‘chunk 단위로 병렬처리이니까, thread 들이 reader 로직에서 각자 paging query를 수행하여 10개 씩 순차적으로 가져오고, 그 결과를 그대로 chunk로 만들어 handling 할 것이다.’ 라고 예상했습니다.
각 chunk가 아래 그림 처럼, order by 기준 1~10 / 11~20 / 21~30 번째 item으로 구성될 것이라고 생각했던 것이죠.
PagingItemReader는 thread-safe 합니다.
 그림-1
그림-1
하지만 실제로 돌려 보니 이런 결과가!
1
2
3
4
5
6
7
8
2022-12-11 22:01:28 [thread-pool-2] [INFO ] [TestStepConfig.java]lambda$processor$0(110) : ### processing item id=02
2022-12-11 22:01:28 [thread-pool-3] [INFO ] [TestStepConfig.java]lambda$processor$0(110) : ### processing item id=01
2022-12-11 22:01:28 [thread-pool-1] [INFO ] [TestStepConfig.java]lambda$processor$0(110) : ### processing item id=03
...
2022-12-11 22:01:29 [thread-pool-2] [INFO ] [TestStepConfig.java]lambda$processor$0(110) : ### processing item id=09
2022-12-11 22:01:29 [thread-pool-3] [INFO ] [TestStepConfig.java]lambda$processor$0(110) : ### processing item id=13
2022-12-11 22:01:29 [thread-pool-1] [INFO ] [TestStepConfig.java]lambda$processor$0(110) : ### processing item id=11
...
1, 2, 3번 thread에서 id=1~30 item를 골고루 처리하고 있습니다.
어떻게 된 것일까?
실제 thread에서 수행되는 로직을 따라가 보면… AbstractPagingItemReader::doRead, ChunkOrientedTasklet::execute, SimpleChunkProvider::provide 에 답이 있습니다.
이해를 돕기 위해 코드에서 불필요한 부분은 생략했습니다.
1
2
3
4
5
6
7
public class ChunkOrientedTasklet<I> implements Tasklet {
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
Chunk<I> inputs = chunkProvider.provide(contribution); // doRead
chunkProcessor.process(contribution, inputs); // doProcess + doWrite
...
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
public class SimpleChunkProvider<I> ... {
public Chunk<I> provide(final StepContribution contribution) throws Exception {
final Chunk<I> inputs = new Chunk<I>();
repeatOperations.iterate(new RepeatCallback() {
public RepeatStatus doInIteration(final RepeatContext context) throws Exception {
I item = read(contribution, inputs); // itemReader.doRead
inputs.add(item);
return RepeatStatus.CONTINUABLE;
}
});
return inputs;
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public abstract class AbstractPagingItemReader<T> ... {
protected volatile List<T> results;
protected T doRead() throws Exception {
synchronized (lock) {
if (results == null || current >= pageSize) {
doReadPage(); // 구현체의 doReadPage
page++;
if (current >= pageSize) {
current = 0;
}
}
int next = current++;
return (next < results.size()) ? results.get(next) : null;
}
}
}
1
2
3
4
5
6
public class 구현체PagingItemReader<T> extends AbstractPagingItemReader<T> ... {
protected void doReadPage() {
...
results.addAll(result);
}
}
따라서 실제로는 아래 그림 처럼 동작합니다.

결과적으로 예제 케이스 thread-1, 2, 3에서 다루는 chunk 안에는 1~30 사이의 데이터가 섞여 들어가게 됩니다.
왜 이렇게 처리할까요?
- chunk size가 커서 한 chunk를 처리하는데 시간이 오래 걸린다면 최대한 thread들을 쉬지 않고 굴려야 합니다.
- paging query 결과를 읽어온 thread가 그대로 전담해서 처리한다면, 마지막 chunk 쯔음에 가서는 나머지 thread들은 놀고 있을 가능성이 큽니다.
- 반면 thread들이 paging query result를 one by one으로 경쟁적으로 가져가서 처리하게 되면 가능한 모든 thread가 놀지 않고 process, write를 수행한다는 장점이 있습니다.
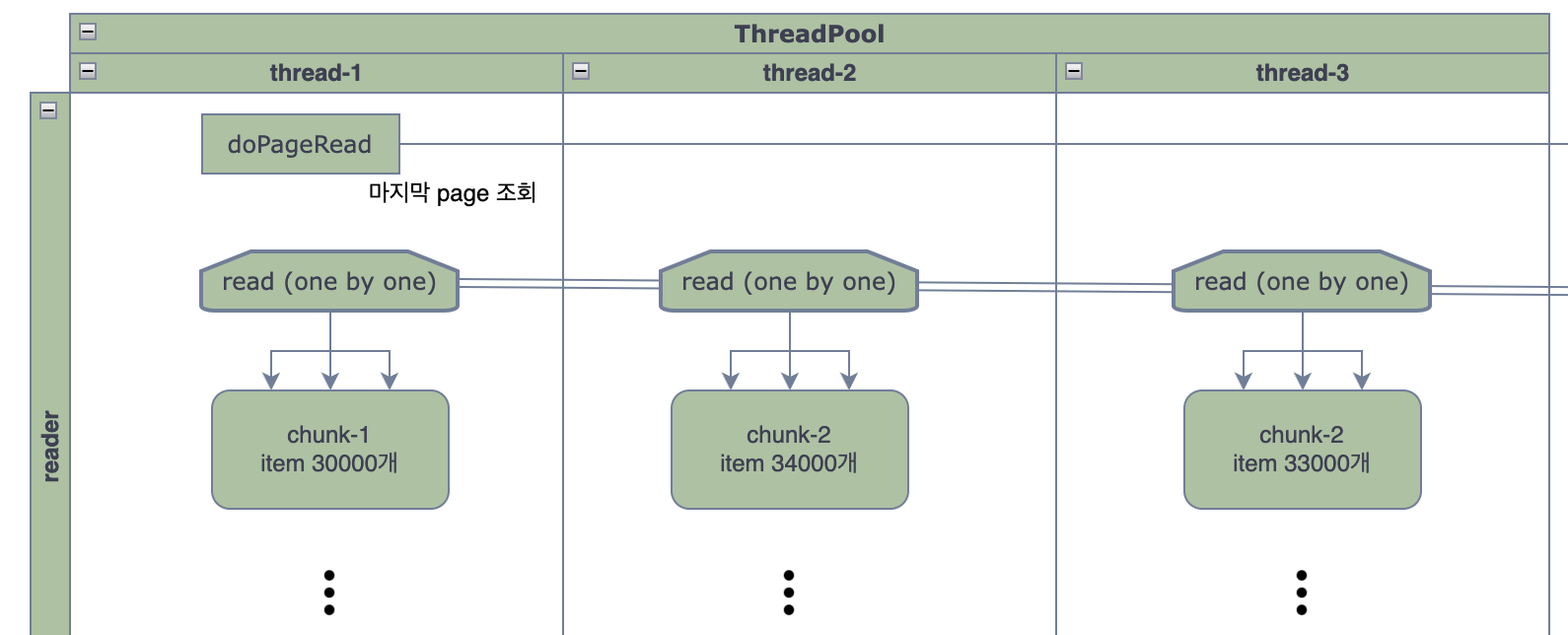 그림-3
그림-3
롤백은 어떻게 될까요?
(TaskletStep::doExecute 참조) 각 thread가 chunk를 처리하기 전에 transaction을 새로 시작하기 때문에, 롤백은 chunk 단위로 일어납니다. 그림-2에서 chunk-2 처리 중 롤백이 일어난다면, [2, 5, 7, 10, … 11, …, 22…] 에 해당하는 item들이 롤백됩니다. Exception이 발생하기 전 이미 처리를 시작한 chunk-1, chunk-3은 커밋됩니다.
그렇다면 중단 지점 부터 재시작은 어떻게 될까요?
(AbstractItemCountingItemStreamItemReader::setSaveState docs 참조)
Set the flag that determines whether to save internal data for ExecutionContext. Only switch this to false if you don’t want to save any state from this stream, and you don’t need it to be restartable.
Always set it to false if the reader is being used in a concurrent environment.
chunk-2가 실패하고 chunk-1, chunk-3은 정상처리 완료된 상태이면 어디서 부터 다시 읽어와야 할까요?
병렬처리 환경에서 중단지점 부터 재시작은 원하는 동작이 아닌 것이 보통입니다.
(재시작 방지를 위해 직접 reader.setSaveState(false) 호출 권장)
보통은 아래 두 가지 선택지 중 하나를 택해서 진행하게 됩니다.
- 병렬처리를 이용해서 잡을 빨리 수행하고, 중간 실패 시 전체 롤백하고 재시작 하는 방안
- 순차처리를 이용하고, 중간 실패 시 중단지점부터 재시작 하는 방안
page 조회 단위로 순차적으로 처리하여 중단 지점 부터 재시작해도 문제없는 병렬 처리 방법은 없을까요?
- reader가 병렬이 아니게끔 만들어 문제 회피하는 방식
- AsyncItemProcessor / AsyncItemWriter
- 보통 배치에서 오래 걸리는 부분은 processor이기 때문에, processor만 병렬로 처리해도 충분한 경우가 대부분
- 기존 processor, writer에 delegate 하는 방식이기 때문에 기존 로직 변경 없이 사용 가능
AsyncItem*사용하면 병렬처리 + 중단지점 부터 재시작 가능
- query where 절의 범위를 다르게 설정하여 query 자체도 병렬 처리하는 방식
- Partitioning
- multi-threaded step은 query 자체는 한곳에서 처리하지만, partitioning은 query 자체도 병렬로 날린다.
- 구성이 더 복잡하고 번거롭다는 단점.