(ES) 인덱스 구조와 Data streams
(ES) 인덱스 구조와 Data streams
Datastream - 새로운 Elasticsearch 데이터 구조 이해하기
ES 저장 구조
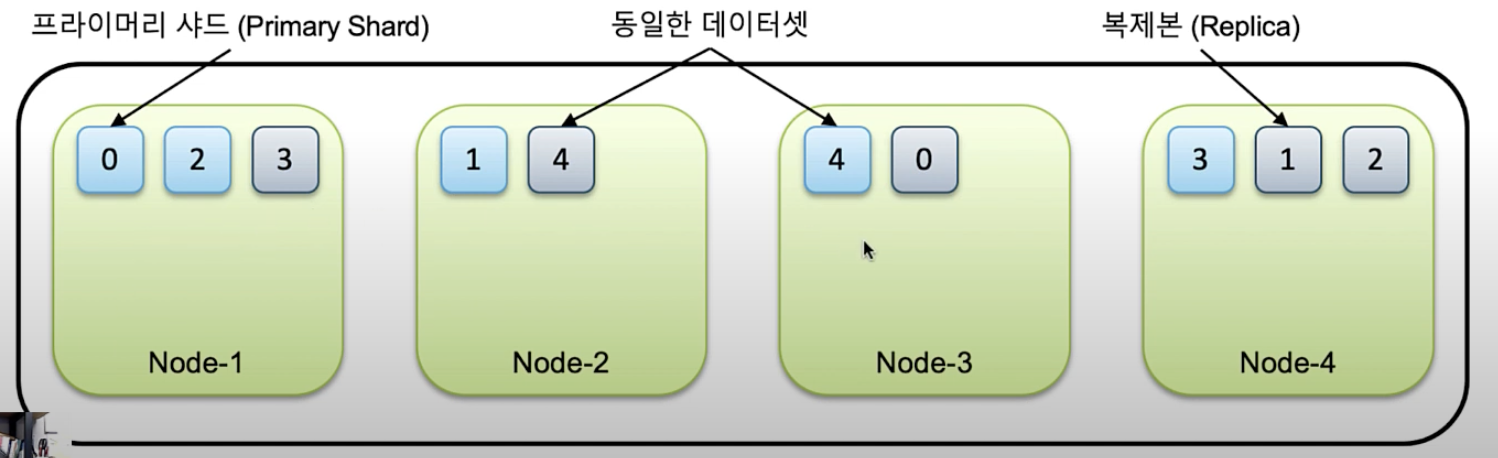
- 클러스터 > 노드 > 샤드
- 하나의 인덱스가 여러 샤드에 나뉘어 저장되는 방식
- 카프카와 비슷하게 샤드를 나누고 replica를 나눠가져서 노드 하나가 다운이 되어도 나머지 노드에서 가지고 있는 샤드로 복원이 가능한 구조.
- 어떤 인덱스가 몇개의 샤드에 나뉘어져 저장될 것인지는 인덱스 생성 할 때 처음에만 설정 가능. (수평확장은 어렵다)
적절한 샤드 개수?
- 샤드는 인덱스 마다 생성이 되기 때문에, 샤드를 너무 많이 생성하게 될 수도 있다는 점을 주의해야 함.
- 특히 인덱스를 일간으로 나누는 경우, 샤드 5개이면 매일 5개의 샤드가 새로 생성되는 것.
- 이런 인덱스패턴이 10개이면 매일 10*5 개의 샤드 생성
- 1년 동안 10*5*365 개의 샤드가 생성됨
- 그래서 7.x 부터는 샤드 개수 디폴트 값은 1개.
Data streams?
- 인덱스는 보통 월간/일간으로 분리해서 쌓게 됨.
- 검색 대상 범위를 축소 할 수 있고, 인덱스 삭제 시 유리하기 때문
logstash 설정
output { elasticsearch { ... index => '%{[@metadata][target_index]}-%{+YYYY.MM}' } }
- 월간/일간 인덱스로 분리되어 있는 상황에서 rw를 편하게 하려면 alias가 필요함.
- 클라이언트에서 직접
log-2024.01에 대고 작업 하는 것은 월이 바뀌었을 때 대응이 안되므로, 인덱스 패턴log-*에 대해서 alias 생성.
- 클라이언트에서 직접
단점1 ) 하지만 여전히 r용 alias(log)와 w용 alias(log-{최신})를 분리해야 하는 불편.- 읽기는 전체에 대해서 검색해야 하지만, 쓰기는 최신 인덱스에 대해서만 발생해야 하기 때문.
- 이 단점은
is_write_index설정을 최신 index에 주면 굳이 w 전용 alias 분리하지 않아도 돼서 해결.
- 단점2 ) 월간/일간 인덱스로 분리하긴 했지만 시간으로 끊으면 인덱스 용량이 들쭉날쭉 할 수 있음.
- 인덱스가 일정 크기가 되었을 때 인덱스 분리하기 위한 기능인 rollover가 있긴 하지만…
- rollover하기 위해서는 alias에 대고 rollover API를 직접 트리거해야 하는 불편.
이 단점을 해소하기 위해 나온 것이 => Data streams
Index Lifecycle Policy 기반으로 자동으로 인덱스 쪼개주는 기능
This post is licensed under CC BY 4.0 by the author.