REST api / RESTful 이란.
REST (Representational State Transfer)
[!info] An API that provides network-based access to resources via a uniform interface of self-descriptive messages containing hypertext to indicate potential state transitions might be part of an overall system that is a RESTful application(link) - Roy T. Fielding
- self-descriptive message?
- 메시지 자체가 자기 자신을 설명하는 메시지. “어디로 가는가? 어떤 동작을 하는가?” 등이 메시지에 나타나야 함
- 메시지를 제공하는 서버, 해석하는 클라이언트에 대한 의존이나 종속 없이 메시지가 자기 자신을 설명하게 되면, 어떤 서버나 클라이언트에서도 메시지를 해석할 수 있다.
- potential state transition?
- (HATEOAS, Hypermedia as the Engine of Application State)
- 응답 데이터와 관련된 요청
_links를 같이 내려주어 클라이언트에서 동적으로 url 탐색 또는 명령 요청 할 수 있도록 하는 것 - URI 체계에 대해 미리 알고 있지 않아도 전체 리소스 집합을 탐색 가능
- HATEOAS 까지 적용하는 경우는 잘 못봤다.

즉, 자원(Resource), 행위(Verb), 표현(Representation) 세 가지로 구성되는 웹(HTTP)에서 사용되는 아키텍쳐 스타일을 의미한다.
- 자원 ?
- 실제 데이터와 URI. “DB에 들어가 있는 특정 레코드”같은 구체적 데이터를 의미할 수도 있고, “메인 페이지”와 같은 추상적인 데이터를 의미할 수도 있음.
- 이러한 데이터들과 그에 접근하기 위한 URI를 자원이라 함.
- 행위 ?
- 자원에 대한 액션이라고 생각하면 되며 HTTP Method로 행위를 나타냄
- 표현 ?
- 리퀘스트에 대한 응답으로 반환되는 자원의 표현을 의미
- 예를 들어 똑같은
asdf라는 문자열을 응답으로 주더라도 content-type에 따라 다른 형태의 표현이 가능하다는 것
REST API 설계 시 생각해야 할 점?
기본 전제
URI는 자원을 가리키는데만 사용된다. (자원에 대한 액션이 URI에 포함되지 않는다.)
- 예를 들면
/people까지만.
자원에 대한 액션(행위)이 곧 HTTP Method (GET, POST, PUT, DELETE, ….)
- 자원에 어떤 액션을 할 지는 HTTP Method로 지정.
- 예를 들어 자원을 삭제할 때는
DELETE /people/umbum
자원, 행위, 표현을 분리해서 구성할 때의 장점?
- 이렇게 구성하면 표현력이 좋아진다.
- 액션과 자원이 분리되어 있기 때문에 REST api 메시지가 의도하는 작업이 잘 나타남. (이로 인해 좀 더 self-descriptive한 메시지가 된다)
- 그 밖에 캐시라던가, 클라이언트-서버 구조라던가 하는 얘기가 있지만 직접 REST api를 써보면서 경험한 장점은 이게 제일 컸던 것 같음
[!info] 하지만 경우에 따라 URI에 액션을 명시해야 하는 경우가 있는 등 항상 잘 들어맞지는 않음.
Stateless
- 어떤 작업을 위한 상태 정보를 따로 저장하고 있지 않는다는걸 의미
- 상태를 저장하게 되면 상태에 따라 같은 요청에 대한 응답이 다를 수 있는데, 이러한 상황을 피하기 위함으로 보임
- 예를 들어 여러 Open API들 써보면 인증에 대한 부분을 매번 쿠키에 id/pw를 넣어서 보내거나, 토큰을 따로 발급받아서 매번 토큰을 붙여서 보낸다. 각각의 리퀘스트에 대한 상태를 저장하지 않고 독립적으로 처리되기 때문.
- 가능하면 stateless하게 설계하는 것이 side-effect을 줄이는데 도움이 된다. (함수형이 그렇듯이)
Safety와 Idempotence
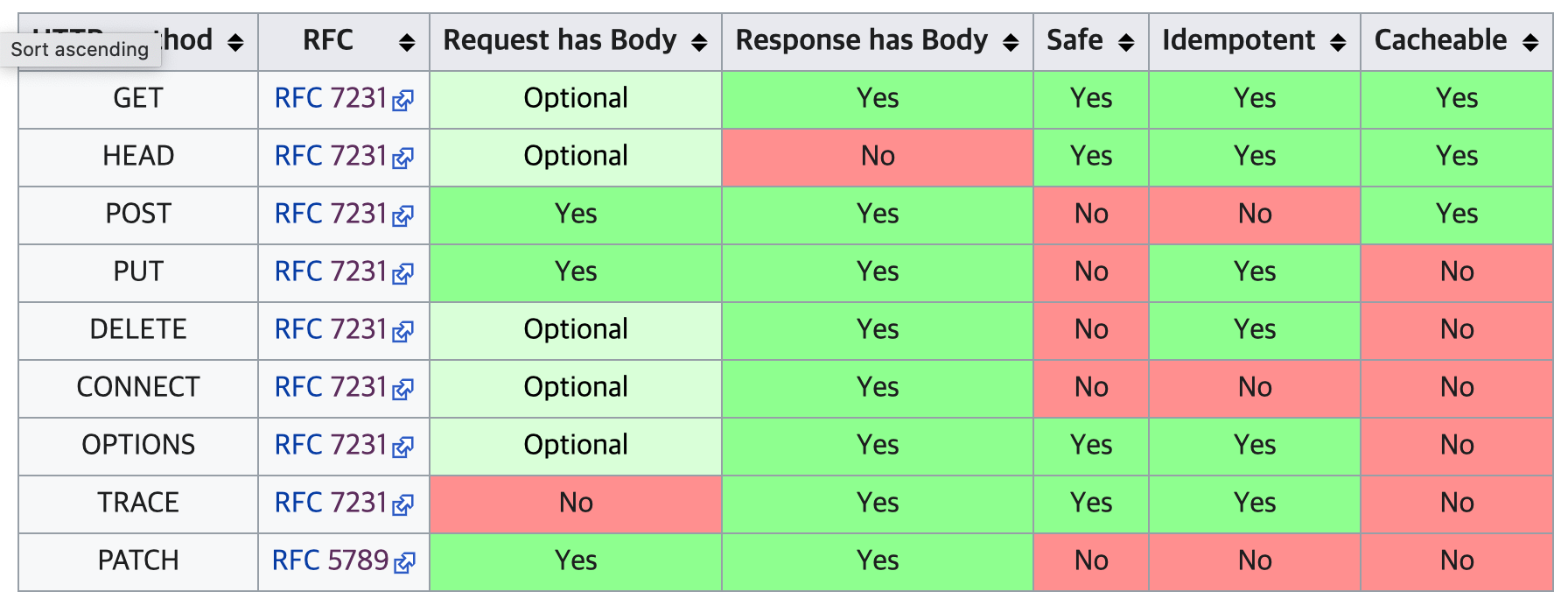 https://en.wikipedia.org/wiki/Hypertext_Transfer_Protocol#Summary_table
https://en.wikipedia.org/wiki/Hypertext_Transfer_Protocol#Summary_table
- Safety는 resource의 상태를 변경하느냐, 아니냐를 의미. 즉 read-only 이냐. 를 의미
- idempotent는 같은 요청을 여러 번 보낸 effect와, 한 번만 보낸 effect가 동일한가. 를 의미
- 즉 ‘a’ 자원 생성 요청을 한 번 보내면 ‘a’가 생성되고, 이후 요청에 대해서는 ‘a’가 이미 존재한다. 라고 내려주고 상태를 변경하지 않으면 이 api는 idempotent하다고 볼 수 있다. 여러 번 요청과 한 번 요청의 effect가 동일 하므로.
[!info] HTTP/서블릿 환경에서 멱등이라는 말은 동일 요청을 서버에서 어떤 잘못된 결과를 야기하지 않고 두 번 이상 이루어질 수 있다는 의미이다. 동일 요청은 동일 응답을 가져야 한다는 의미가 아니고, 요청으로 어떤 side-effect도 발생하지 말아야 한다는 의미도 아니라는 것에 유의하라. - 헤드퍼스트 서블릿 & JSP
자원 생성 및 수정. POST vs PUT vs PATCH
- RFC 2616 POST : POST to a URL creates a child resouce at a server defiend URL
- 자원의 위치(id)를 명시하지 않았을 때의 생성
POST /pet- 같은 요청이라도, 보낼 때 마다 내용은 같고 id만 다른
/pet/1, .. /pet/2, ...가 생성될테니 idempotent하지 않다.
- 같은 요청이라도, 보낼 때 마다 내용은 같고 id만 다른
- RFC 2616 PUT: PUT to a URL create/replaces the resource in is entirely at the client defined URL
- 자원의 위치(id)를 클라이언트가 지정할 때의 생성 또는 “대체(replace)”
PUT /pet/1- 처음 요청을 보낼 때는 생성, 이후 부터는 “전체를 대체” 로 동작하도록 할 수 있음.
- 하지만 생성을 PUT에 포함하지 않고 POST를 별도로 제공할 수도 있음.
- “전체를 대체”(replace) 이므로 전체 데이터를 요청에 포함하여 받아야 함.
- 전체를 대체하는 것이므로, 요청 데이터가 같은 경우 idempotent 해야만 함. (항상 같은 값으로 대체하면 결과가 매번 동일할 것임.)
- “일부를 변경”(update)은 부분 수정 이므로, PATCH를 사용하는 편이 좋다.
- 처음 요청을 보낼 때는 생성, 이후 부터는 “전체를 대체” 로 동작하도록 할 수 있음.
- RFC 5789 PATCH : PATCH to a URL updates part of the resource at that client defined URL
- 자원에 대한 partial update
- PATCH는 idempotent를 보장하지 않음. 즉 unsafe, non-idempotent 할 수 있음.
- update 이기 때문. 예를 들어 ++업데이트 한다면 호출 할 때 마다 1씩 증가하게 되므로
multipart file upload는 HTTP POST를 사용해야 한다. Spring에서는 애초에 PUT으로 multipart를 받지 못한다.
HTTP Status Code
- 401 Unauthorized VS 403 Forbidden
- 어떤자원이해당유저에게인가후 접근 가능한 자원이면401
- 아예접근 불가하면403 (다른 사람 자원이라던가)
- 구글은 로그인 실패 시 401이 아니라 200이 내려온다.
- 생각해보면 로그인 이라는 비즈니스가 REST를 적용하기에 적절하지 않을 수도 있다.
- accountInfo 조회, challenge 모두 POST 쓰는 것을 보니 REST 사용하지 않는 듯.
[!warning] REST가 항상 정답은 아니다
Pagination url 설계
Pagination 필요성
- BE단에서 Pagination은 한 번에 메모리에 가져오기에는 너무 크거나, 시간이 오래걸리는 데이터를 나눠서 가져오기 위한 목적이다.
- BE단만 생각하는 엔지니어는 몇천건 정도의 데이터(서버 메모리에 한번에 적재해도 부담없는 사이즈)라면 Pagination 없이 전체 데이터를 가져올 수도 있을 것이다. 이에 따라서 API도 전체 데이터를 반환하도록 구성하고자 할 수 있다.
- 하지만 FE(API)단 Pagination의 목적도 생각해야 한다. 몇천건 정도의 데이터는 서버 메모리에 올리기에는 부담이 없겠지만 저성능 디바이스 메모리에 올리기에는 충분히 부담스러울 수 있다.
- 게다가 해외 등 네트워크 속도가 매우 느린 곳을 감안하면 디바이스가 몇천건 데이터를 수신하도록 구성하는 것은 별로 현명한 선택이 아니다.
- 즉, 서버 스펙이 좋아 BE단 Pagination이 필요치 않은 경우라도, (저성능, 저속도) 디바이스 환경을 고려하여 API 단에서 Pagination을 제공하는 것이 좋다.
Pagination과 sorting
- 일단 API에서 Pagination을 제공하기로 했다면, sorting도 BE 단에서 해서 내려주어야만 한다.
- FE 단에서는 전체 데이터 대상 sorting이 불가하기 때문에 제대로 된 sorting이 불가능하다.
Pagination url param 예시
1
2
3
4
5
/orders?offset=50&fetch=25
fetch 또는 limit
---
/orders?page=1&size=25
spring data jdbc의 Pageable.of(page, size)
Pagination 응답
Aggregation 요청 url 설계
- https://stackoverflow.com/questions/12339504/aggregate-data-in-restful-api
참고 ) 잘 모르겠다면 참고 docs
- Google의 API 디자인 가이드
- ***MS의 API 디자인 지침. 사실 이 것만 봐도 많은 도움이 된다.
- OpenAPI-spec docs. 설득력에 도움
- https://jsonapi.org/- 설득력에 도움
- swagger에서는 이런 식으로 정리함.
- deview - 그런 REST API로 괜찮은가
- 원논문을 정리한 참고할만한 포스팅
- REST 아키텍쳐를 훌륭하게 적용하기 위한 몇 가지 디자인 팁
- URI 이름과 경로를 어떻게 해야할지 좋은 참고 자료.
- https://meetup.toast.com/posts/92
ResponseEntity<>()를 사용해 응답 코드를 내려줄 때 어떤 상황에서는 어떤 코드를 사용해야 하는지까지 잘 정리된 문서
This post is licensed under CC BY 4.0 by the author.