카프카 개요, 장점
카프카 개요, 장점
카프카가 왜 필요한가?
- 카프카는 메시징 시스템이고 [High Throughput, Scale-out, Fault-tolerance] 하다는 장점을 가지고 있음.
- 우선은, 왜 카프카를 써야 하는가?에 대한 근본적인 물음이다. “카프카도 결국 데이터 저장소를 중앙에 두고 insert/select 하는 개념으로 볼 수 있는데 DB를 Queue처럼 사용하면 안되는 것인가? 안된다면 왜 안되는가? “
- 데이터 중앙화 니즈? => 중앙 DB 하나 두면 됨.
- 비동기 때문에 사용한다? => DB가 비동기 지원한다면?
- 분산처리로 인한 성능 => sharding, 분산 DB 사용하면 됨
- 내장애성 => DB도 이중화는 필수임
- 스키마 확장이 불편하다 => NoSQL 쓰면 됨
- 자주 언급되는 이러한 이유들은 생각해보면 DB로 커버가 되는 것 같아서 당위성이 약해보였다. 그니까, 카프카가 우위에 있는 것은 맞는데 핵심적인 이유는 아닌 것 같아서.
- 메시지 큐를 쓰는 이유가 곧 카프카를 쓰는 이유일텐데, DB로는 메시지 큐가 안되는 이유가 뭘까? 성능이 나쁘다면 그런 차이는 어디에서 오는 것인가?
왜 DB를 Queue로 사용하는 것이 부적절한가? (왜 Messaging System이라는 별도 시스템이 필요한가?)
- 세부적인 이유와 예시는 아래 링크를 참조하면 되고
- 요약하면,
- polling 문제. Message Queue에서 비동기 push 지원
- publish 자체는 DB도 비동기 입출력 지원한다면 응답을 기다리지 않아도 되므로 상관없지만
- Messages from a message queue are pushed in real-time instead of periodically polled from a database. 이건 DB가 지원하는 기능이 아니라서.
- (하지만 Kafka는 pull 방식이긴 하다)
- Queue 처럼 사용하려면 index를 걸어야 한다는 문제
- 예를 들어
status != COMPLETE && time=latest조건으로 front에 대항하는 항목을 가져온다고 가정하면 - 항목을 빠르게 가져오기 위해 index를 걸어야 하는데, index는 insert를 느리게 만든다.
- 그리고 쿼리를 보면 알겠지만 전체적으로 shared lock이 걸리게 되는데, 따라서 exclusive lock 획득하려면 기다려야 한다. (성능↓)
- 예를 들어
- 상태 업데이트 문제
- 기본적으로 한 테이블 = 한 Queue로 생각하고 CRUD가 일어날텐데, 작업 항목이 완료되면 항목을 Update 하며 이 때 exclusive lock이 걸린다.
- index가 걸려 있으므로 해당 항목에만 lock이 걸리겠지만, 배타 lock이라서 해당 항목이 검색 범위에 포함되는 select 쿼리도 대기해야 한다. (성능↓)
- deadlock이나 race condition 문제에 대해서도 신경써야 한다.
Clean-Up 문제
- delete도 인덱스를 정리해야해서 느리다.
- 더 큰 문제는, 7일 동안 저장하고 있다가 삭제 같은 작업을 앱단에서 메뉴얼하게 처리해주어야 한다는 점이다.
- 그리고 이 모든 것들을 개발자가 직접 핸들링 해야 한다는 복잡함
- polling 문제. Message Queue에서 비동기 push 지원
- 이러한 차이는 결국, 본질적으로 태생이 다르기 때문에 존재한다. DB는 ACID를 보장하는 CRUD를 전제 하지만 , 메시지큐는 해결하려는 문제, 근간 부터가 다르다.
- 애초에 해결하려는 목적이 다르기 때문에 이렇게 동작하게끔 되어 있는 RDB를 Queue로 사용하는 것은 가능은 하지만 태생적인 설계로 인하여 비효율적일 수 밖에 없다.
- 그리고 이런 비효율은 결국 성능 문제로 이어진다. [1. 성능 잘 나오고 2. 쓰기 편하면] 대체로 문제가 없지만 해결하고자 하는 문제가 다른데도 이 2가지가 좋은 경우는 거의 없다.
[!info] DB와 Message Queue 뿐만 아니라, [시계열 데이터 처리용 시스템, 하둡, 로그 모니터링용 시스템, …등]으로 데이터 스토어가 분화된 이유도 마찬가지다.
DB로도 데이터 저장하고 뿌려주는 것이 가능은 하지만, 본질적으로 그런 용도로 만들어 진 것이 아니기 때문에 fit하게 들어맞지가 않고
데이터의 특성과 목적에 맞게 최적화된 새로운 시스템이 필요한 것이다.
링크드인은 왜 카프카를 만들었나? 카프카로 해결하고자 하는 문제는 무엇이었나?
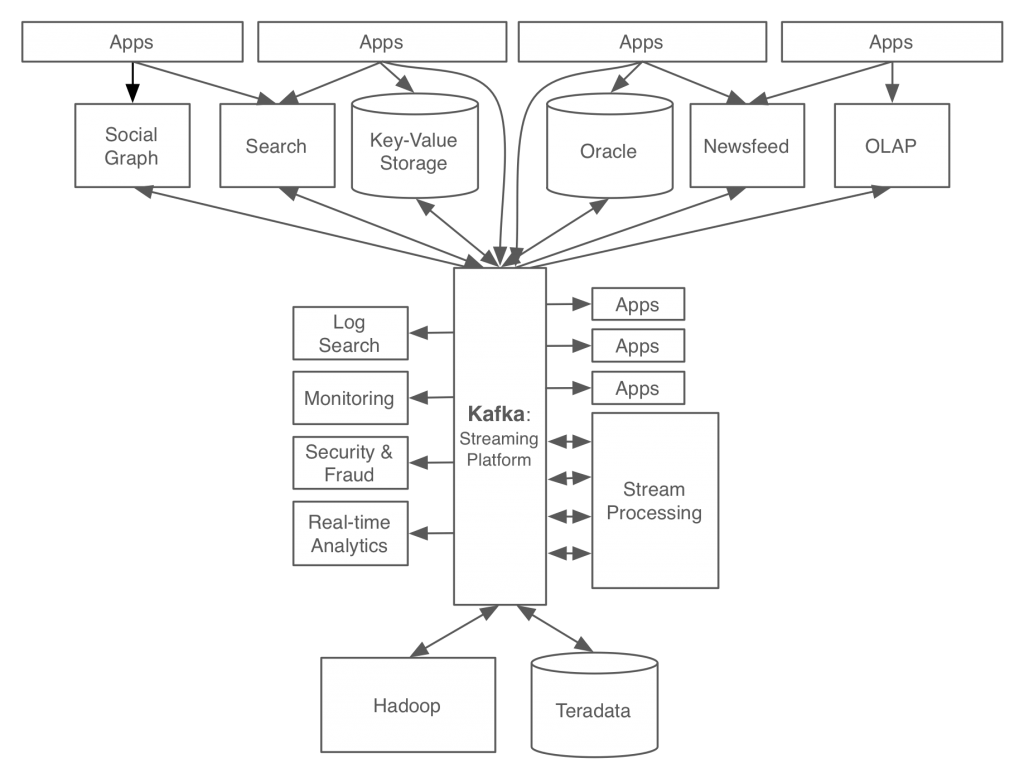 책 1장, https://www.confluent.io/blog/event-streaming-platform-1/
책 1장, https://www.confluent.io/blog/event-streaming-platform-1/
- 카프카를 메시지 전달의 중앙 플랫폼으로 두고 기업에서 필요한 모든 데이터 시스템 뿐만 아니라 마이크로서비스, SaaS 서비스 등과 연결된 파이프라인을 만드는 것을 목표로 개발했음.
- 이전에는 이렇게 중앙화된 데이터 스트리밍 플랫폼이 없었다. (성능 등의 문제로)
- 직접 연결 안하고 중앙의 카프카에서 받아오니까 fail-over에도 강하고 (갑자기 dst나 src 서버가 다운되는 경우에 대한 대비를 각자 할 필요가 없어지니까)
- fail-over 관점도 중요하긴 한데, 그 보다는 필요한 데이터를 한 곳에서 중앙 집중 관리 할 수 있으니 서버들 간의 데이터 의존 그래프가 많이 간소화 된다는 것
- 새로운 서버를 추가/제거 할 때 이런저런 연동 신경쓸 것 없이 카프카만 연결해주면 되니까 확장성 ⬆ / 게다가 카프카 자체도 클러스터 확장이 매우 쉬움
카프카 개요
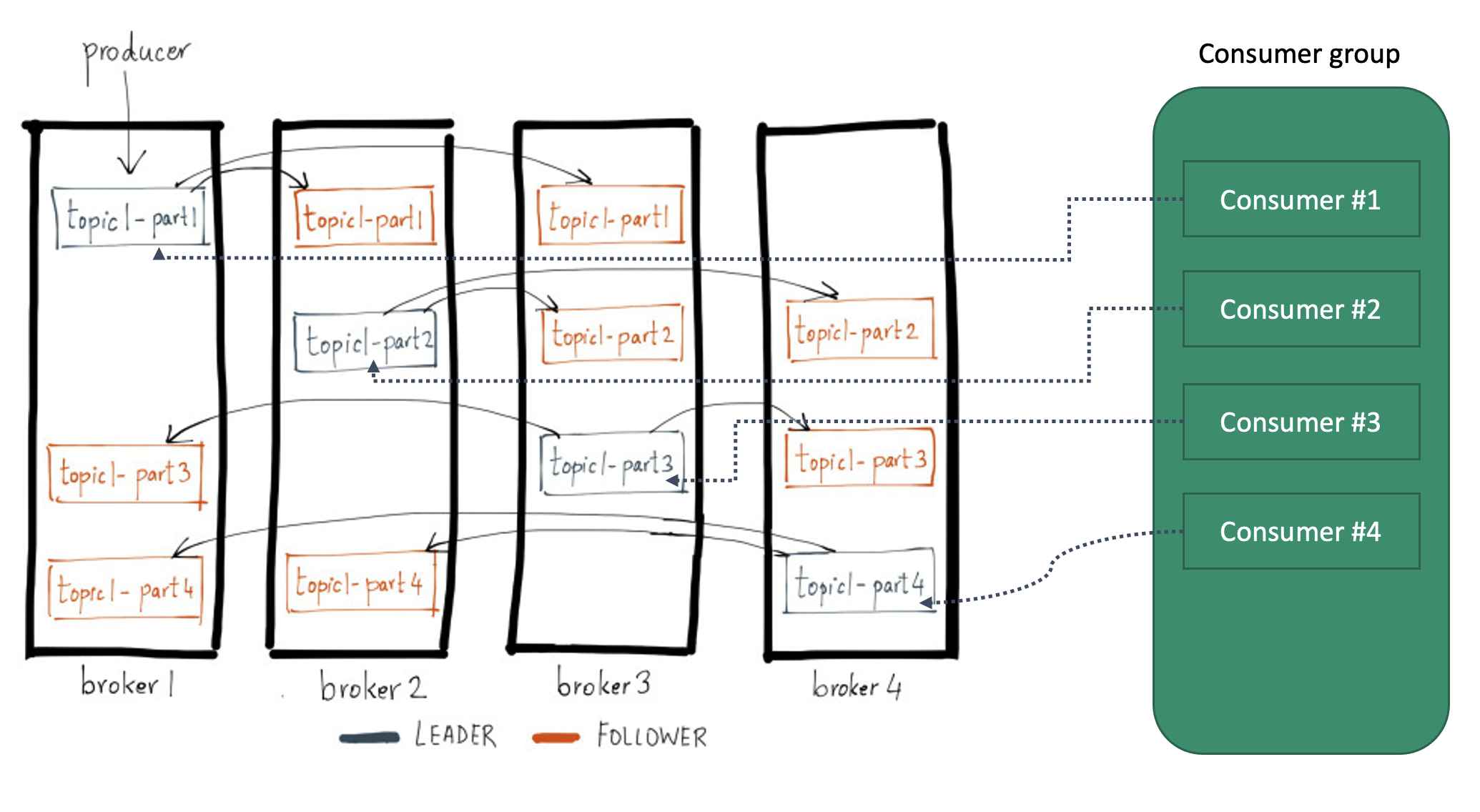 https://www.confluent.io/blog/hands-free-kafka-replication-a-lesson-in-operational-simplicity/#
https://www.confluent.io/blog/hands-free-kafka-replication-a-lesson-in-operational-simplicity/#
- broker 수 4,
--partitions 4 --replication-factor 3 - 읽기, 쓰기(produce, consume)는 리더에서만 발생함. 팔로워는 단순 pull해서 리플리케이션만 하고 읽기/쓰기에는 관여하지 않음
- partition은 분산/병렬 처리 관점, replica는 fail-over 관점
- 읽기, 쓰기(produce, consume)는 리더에서만 발생함. 팔로워는 단순 pull해서 리플리케이션만 하고 읽기/쓰기에는 관여하지 않음
- partition은 분산/병렬 처리 관점, replica는 fail-over 관점
- 카프카는 OS 페이지 캐시를 사용하기 때문에 JVM 힙 사이즈는 적당히 설정하고, 서버에 단독으로 띄워 페이지 캐시를 모두 활용할 수 있도록 하는 것이 좋다
- 어떤 토픽에 대해서 물리서버 1대에 파티션이 1개씩만 들어가게끔 설정할 필요는 없음. 파티션을 더 넣어주면 그 만큼 병렬처리 가능하므로 처리량이 늘어날 수는 있음. 그러나 무한정 늘리면 오히려 악영향이니 파티션은 목표처리량에 맞게 점진적으로 늘리는 것이 좋음
- 하나의 컨슈머와 프로듀서는 한 파티션에 연결된다고 생각하면 처리속도는 컨슈머와 프로듀서의 속도에 영향을 받기 때문임
- UI 툴은 CMAK 사용한다
- 카프카는 파티션 내에서의 순서만 보장한다. 파티션 간의 데이터 순서는 보장이 안된다.
- 즉, 순서 보장이 필요한 경우 파티션을 1개로 해야 한다. ⇒ 분산처리 X ⇒ 처리량 ⬇
- Key를 사용하면, 특정 파티션으로만 데이터를 프로듀스/컨슘 할 수 있다.
- 다른 메시지큐 처럼 소비하면 없어지나? - X 기본 7일 동안 보관한다.
- 그래서 필요하다면 이미 가져온 데이터를 다시 가져 올 수도 있고,
- 여러 컨슈머 그룹에서 각자의 offset으로 메시지를 가져갈 수도 있다.
- 기타 상세한 내용은 책과 필기를 참조. ISR과 ack에 대한 내용 등등.
- 카프카 컨슈머
- 토픽 네이밍 방법
This post is licensed under CC BY 4.0 by the author.