카프카 컨슈머
카프카 컨슈머
옵션, 예제
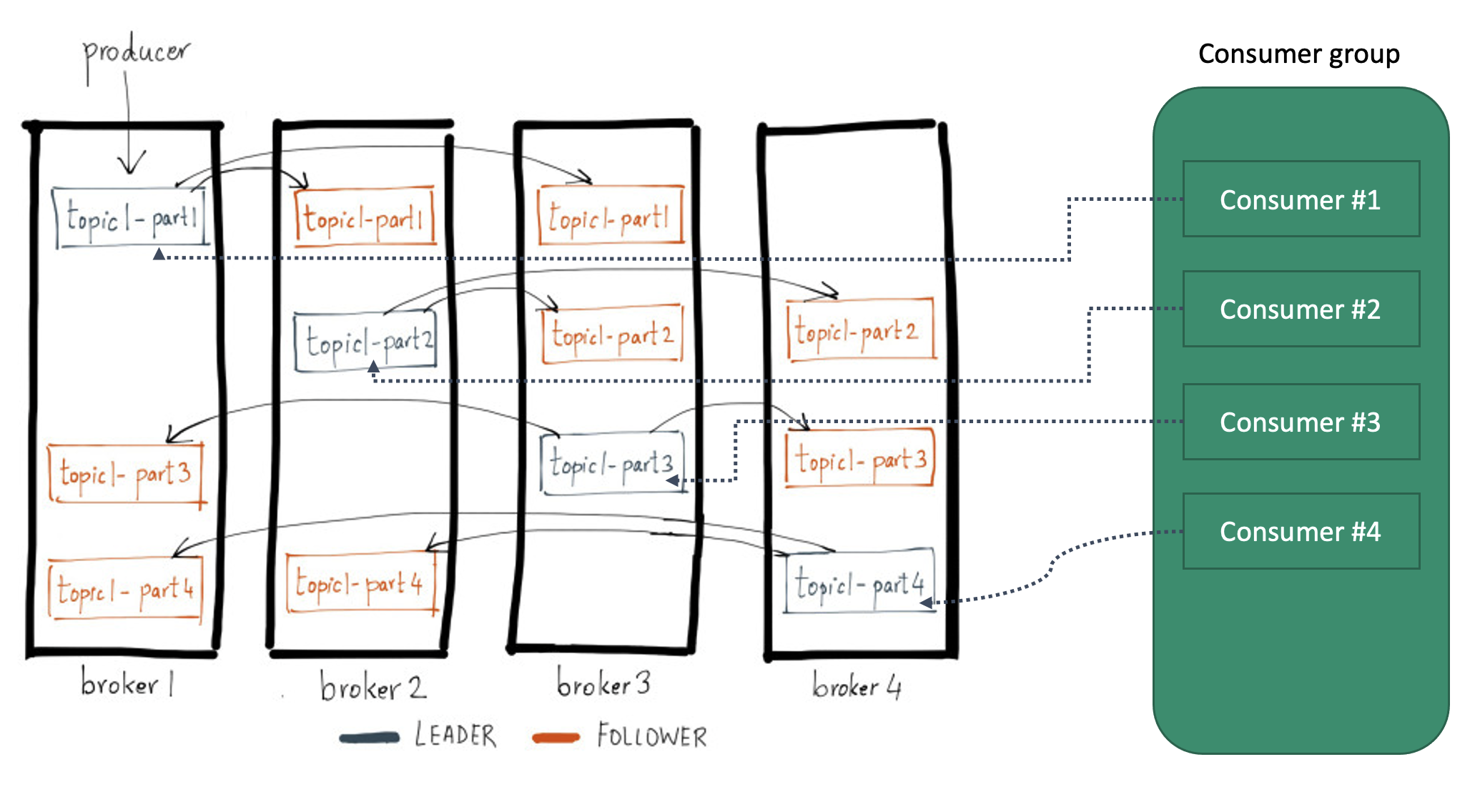
- 컨슈머? 파티션 리더에게 메시지 가져오기 (Consume)
- 다른 메시지큐 처럼 소비하면 없어지나? – X
- 기본값 7일 동안 저장했다가 삭제
- 필요하다면 이미 가져온 데이터도 다시 가져올 수 있음
- 여러 컨슈머 그룹에서 메시지 수신 가능
컨슈머 중요 옵션
group.id컨슈머 그룹 식별자- fetch 관련
fetch.min.bytes한 번에 가져오는 데이터의 최소 사이즈. 지정한 사이즈 보다 작은 경우 요청에 응답하지 않고 데이터가 누적될 때 까지 기다림. (default 1byte)fetch.max.wait.ms사이즈가 작아서 기다린다면 최대 몇 초 동안 기다릴건지? (default 500ms)- max-wait 시간 지나면 쌓인 데이터가 min-bytes 보다 작아도 그냥 컨슈머로 보내기 때문에, min-bytes가 실제 수신하게 되는 데이터의 최소 사이즈는 아님.
- heartbeat 관련
- 컨슈머가 살았는지 죽었는지는 컨슈머가 지속적으로 하트비트를 보내는 것으로 판단함
- 하트비트 관련 상세 내용은 다음 링크 하단의HeartBeat 스레드 참조
session.timeout.ms- 컨슈머<> 브로커 세션 타임 아웃 제한 시간. 지정된 시간 동안 컨슈머가 그룹 코디네이터에게 하트비트를 보내지 않으면 컨슈머 장애로 판단하고 리밸런스 진행함.
heartbeat.interval.ms- 이 하트비트를 얼마 간격으로 보낼건지 지정하는 옵션 (보통 세션 타임아웃의 1/3로 설정)
max.poll.interval.msHeartBeatThread만 poll하고KafkaConsumer는 poll하지 않아서 실제로 메시지를 가져가지 않는 경우를 대비한 옵션.- 지정된 시간 동안 컨슈머가 poll 호출하지 않으면 장애라고 판단함. 위 d2 링크 참조.
max.in.flight.requests.per.connection
컨슈머로 읽어오기 (콘솔 예제)
1
2
./kafka-console-consumer.sh --bootstrap-server $KAFKA_CLUSTER --topic peter-topic --group peter-consumer-group --partition 0 --from-beginning
./kafka-console-consumer.sh --bootstrap-server $KAFKA_CLUSTER --topic peter-topic --group peter-consumer-group --partition 0 --offset 1
http://10.168.241.137:9000/clusters/dev-umbum-kafka/consumers
토픽, 컨슈머 오프셋 CMAK에서 확인 가능
컨슈머로 읽어오기 (코드 예제)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
public class KafkaBookConsumer1 {
@Test
public void main() {
Properties props = new Properties();
props.put("bootstrap.servers", "10.168.249.27:9092,10.168.249.17:9092,10.168.249.4:9092");
props.put("group.id", "peter-consumer");
props.put("enable.auto.commit", "true");
props.put("auto.offset.reset", "latest");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("peter-topic"));
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("Topic: %s, Partition: %s, Offset: %d, Key: %s, Value: %s\n", record.topic(), record.partition(), record.offset(), record.key(), record.value());
}
} finally {
consumer.close();
}
}
}
- 위는 그냥 예제 코드이고, 실제 사용할 때는 코드를 이렇게 imperative하게 작성하여 while true poll 하지는 않는다.
- spring-kafka 를 사용한다. (
@KafkaListener)
파티션과 메시지 순서 보장
카프카는 파티션 내에서의 순서만 보장한다. 파티션 간의 데이터 순서는 보장이 안된다.
a b c d e 1 2 3 4 5차례대로 입력하는 경우

- 위와 같이 파티션에 적재 되었다고 가정하면
- 파티션의 앞에서 부터 offset을 증가시키며 컨슘하기 때문에 파티션 내의 순서는 보장 됨.
- e.g., 전체 결과 내에서
a d 1 4는 반드시 이 순서대로 여야 함.d가a보다 선행할 수 없음
- e.g., 전체 결과 내에서
- 파티션 간의 순서는 보장이 안됨
- e.g.,
b a c가 어떤 순서대로 받아오게 될지는 보장이 되지 않는다.
- e.g.,
- 파티션의 앞에서 부터 offset을 증가시키며 컨슘하기 때문에 파티션 내의 순서는 보장 됨.
- 극단적으로 전체 결과가
a d 1 4 b e 2 5 c 3가 될 수도 있음
그렇다면, 순서 보장이 필요하다면 어떻게 해야?
파티션 : 컨슈머 수
case : 파티션 수 < 컨슈머 수
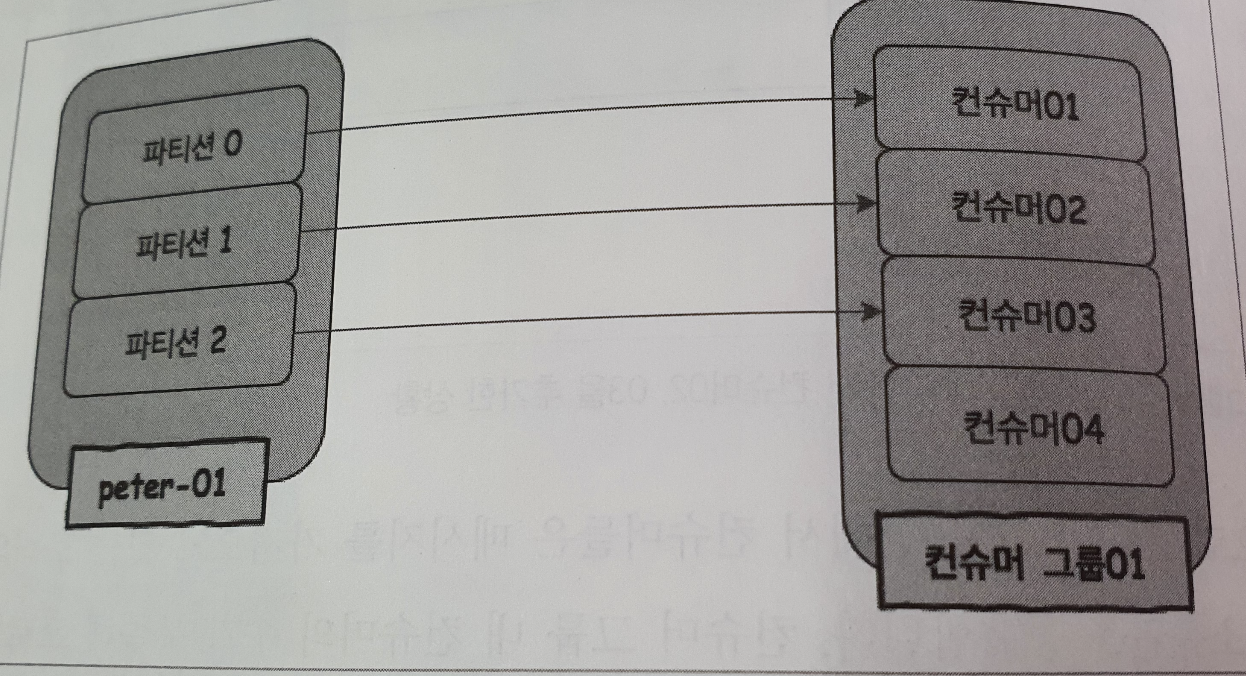
컨슈머 그룹 안에서, 하나의 파티션에는 하나의 컨슈머만 연결할 수 있다.
하나의 파티션에 두개의 컨슈머가 연결되면 안정적으로 메시지 순서를 보장할 수 없기 때문임.
따라서 컨슈머04는 놀게 된다.
case : 파티션 수 > 컨슈머 수
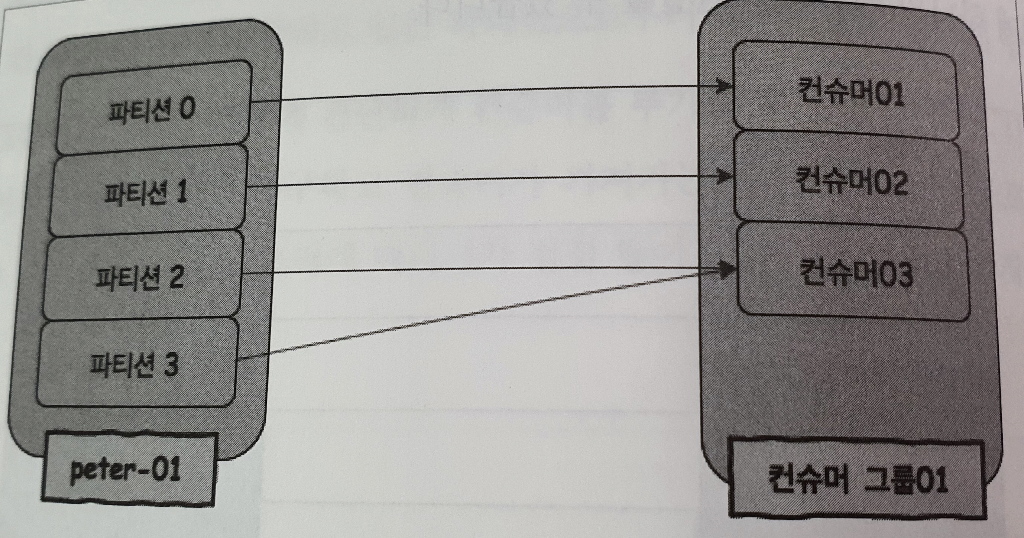
컨슈머3이 처리속도가 2배가 아니라면 파티션 2,3에 있는 메시지 처리가 지연될 것이므로 새로운 컨슈머4를 추가해주는 것이 좋음.
커밋과 오프셋
- 컨슈머 그룹의 컨슈머들은 각각의 파티션에 대해 자신이 가져간 메시지의 위치 정보(offset)을 기록하고 있음.
- 즉, 어디까지 읽었는지? (=어디서 부터 읽어야 할지?)
- 이 컨슈머 오프셋 정보도, 카프카 토픽으로 관리함. (0.9≤v)
- __consumer_offsets 토픽
- http://10.168.241.137:9000/clusters/dev-umbum-kafka/topics
- 옛날 버전의 컨슈머(v<0.9)는 컨슈머 오프셋을 주키퍼(지노드)에 저장 (성능에 문제 있음)
- 각 파티션에 대해 현재 위치를 업데이트 하는 동작을 commit 이라고 함.
- 관련 옵션
enable.auto.commit- 오프셋을 자동으로 커밋 할 것인지 여부
- 설정 시,
poll()호출할 때 마다 커밋할 시간(인터벌)이 되었는지 체크하고, 인터벌이 지났다면 이전poll()요청을 통해서 가져온 마지막 오프셋 을 커밋함.
auto.commit.interval.ms- 오프셋 오토 커밋 인터벌 (default : 5s)
중복과 누락
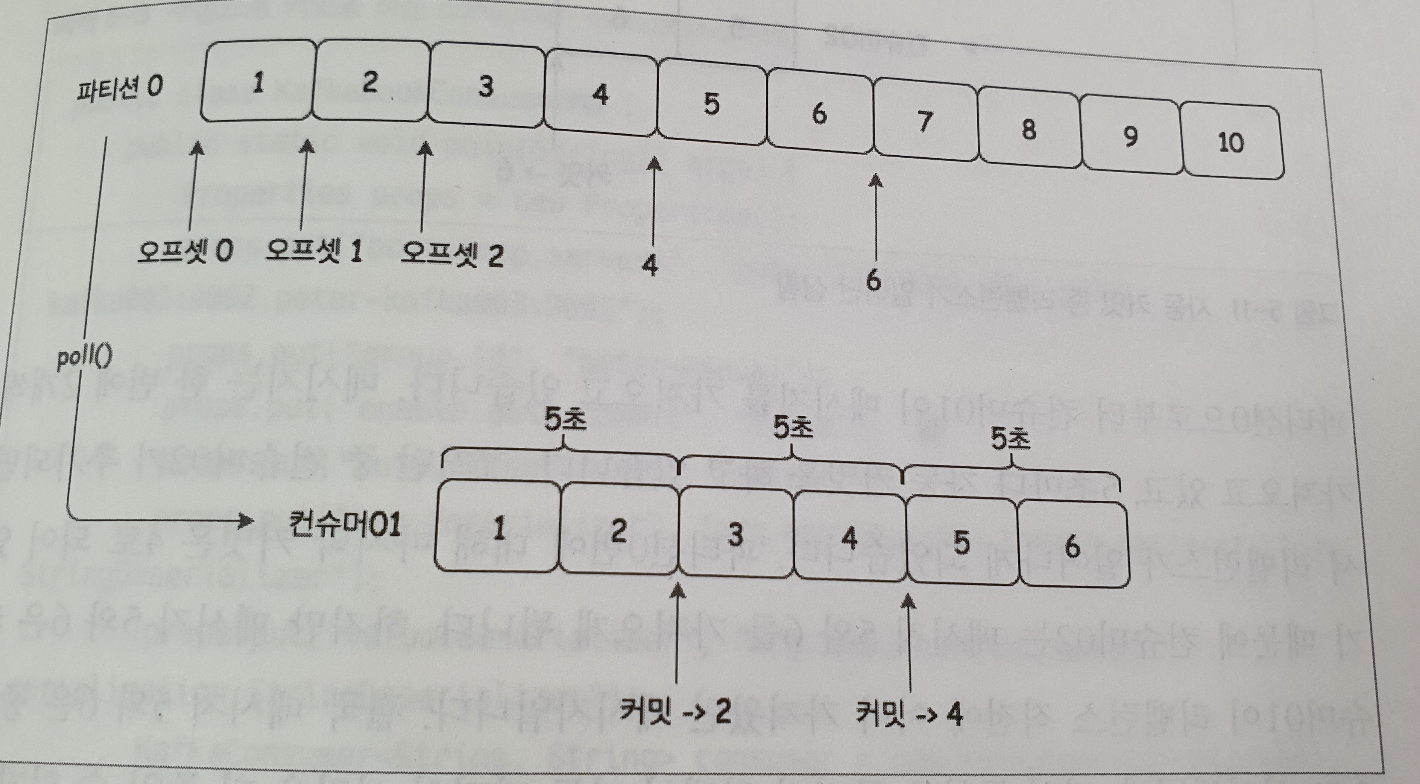
컨슈머01이 아래와 같이 진행 했을 때
A.1, 2 를 가져옴
B.3, 4 를 가져오면서 2를 커밋
C.5, 6 을 가져 오면서 4를 커밋
중복이 발생하는 케이스
컨슈머1이 B 진행 후 처리하다 오류 및 리밸런싱 (컨슈머2가 이어받음)
⇒ offset은 2 이므로, 새로운 컨슈머2가3, 4 를 다시 컨슘 ⇒ 중복
누락이 발생하는 케이스
클라에서3, 4 처리가 아직 안끝났는데5, 6 가져오면서 4를 커밋(C)
결국3, 4 처리 실패하고 리밸런싱 ⇒ offset은 4이므로, 새로운 컨슈머2는5, 6 부터 컨슘 ⇒ 누락
[!info] 이러한 케이스를 견고하게 막아야 하는 경우, 수동 커밋 방식으로 처리하는 것이 가능함.
특정 파티션만을 지정하여 메시지를 가져와야 하는 경우
- key-value 형태로 파티션에 나뉘어져 저장되어 있고, 특정 파티션의 데이터만 가져와야 하는 경우
- 컨슈머 프로세스가 자동으로 관리되는 경우 (카프카가 관리해줄 필요 없는 경우. 죽으면 알아서 해당 파티션 컨슈머가 다시 뜬다거나)
1
2
3
TopicPartition partition0 = new TopicPartition(topic, 0);
TopicPartition partition1 = new TopicPartition(topic, 1);
consumer.assign(Arrays.asList(partition0, partition1));
특정 offset 부터 메시지 가져오도록 수동 설정 해야 하는 경우
1
consumer.seek(partition0, 2);
파티션과 오프셋 번호를 넘겨주면 컨슈머가 다음 poll() 하는 위치를 지정할 수 있음.
Lag 쌓여 있을 때 컨슈머 리밸런싱 하지 마라
- 일반적으로 consuming 로직이 많이 무겁지 않기 때문에, 1개 thread가 n개의 partition을 컨슘 해서 처리하도록 구성 한다. (최대한 thread를 놀지 않게 하기 위해서)
- e.g.
파티션 수 = 4, pod 수 = 1, concurrency = 2이면, 총 2개의 thread가 각자 2개의 파티션을 맡아서 처리하게 된다. - 여기서 트래픽이 몰려 pod가 2개로 scale-out 되면,
파티션 수 = 4, pod 수 = 2, concurrency = 2이므로, 총 4개의 thread가 파티션을 각각 1개씩 맡아서 처리하게 된다. - 얼핏 들었을 때는
thread 2 -> 4개가 처리하니 2배 더 빨리 처리할 것 같지만,- 실제로 thread 2개가 별로 무리해서 처리하고 있는 상황이 아니었다면 큰 속도 향상은 없고 (특히 nio이면)
- Lag가 intensive하게 쌓이고 있는 상황에서는 컨슈머 리밸런싱으로 인한 처리 지연이 오히려 상황을 악화시킬 수 있다. (그 사이에 Lag이 오히려 더 쌓여서 해소되기 어려워진다.)
이미지 출처 및 참고
카프카, 데이터 플랫폼의 최강자
This post is licensed under CC BY 4.0 by the author.