MS AI Tour 2024.04.30
컨퍼런스는 엄청 딥한 주제 보다는 요즘 이슈가 되는 트렌디한 주제를 얕고 넓게 다루는게 오히려 더 괜찮을 수 있다. 참가자들은 큰 노력 안들이고 트렌디한 주제를 한번 훑어 볼 수 있으니까. 직접 문서 찾아가면서 안봐도 되고…
keynote
LG 생활가전 usage
고객센터에 CS 인입되면 → 운영자가 LLM에 자연어로 질의넣고, → 통계 결과 반환되면, 이거 바탕으로 고객에게 안내.
결국 고객센터 쪽에 활용하네. use case는 우리 회사랑 비슷. 역시 아직까지는 사람이 한 뎁스 껴야 하는 듯.
SK 이노도 비슷하네.
- 사내용 chat bot
- RAG 기반 기술문서 Q&A
스콧 한셀만 V.P.
https://platform.openai.com/playground/complete
oai.azure.com → 요거는 구독 안하면 안됨.
에서 한국어로 질의 잘되는거 보여주려고 하다가… 잘 안됐음 ㅋㅋ;;ㅎㅎ
조승민 solution arch.
https://huggingface.co/spaces/upstage/open-ko-llm-leaderboard 한국어 LLM 랭킹
LM Studio 써서 eeve koeran instruct 요거 모델 로딩하고 테스트 하는 듯 ㅎ
LM Studio도 MS 거였나???
틱토큰이라는 BP 기반 토크나이너? 바이트 페어 인코딩 기반 토크나이저. cl100k_base
환 이라는 글자는 한개 토큰으로 인식. ㅎ+ㅗ+ㅏ+ㄴ 으로 인식하지 않고.
한글은 토큰의 개수가 2.5배에 가까움. 유니코드이기 때문에… 유니코드 하나 하나가 다 토큰임. 그래서 더 어렵다.
정구형 nvidia
NVIDIA AI lisence 가 있어야 사용 가능. 유료임. B2B
NIM (NVIDIA Inference Microservices)
이거 뭐 추론 모델을 MSA 컨테이너 형태로 제공하나봄?
새로운 모델이 나오면 이거 빨리빨리 써보고 싶어 하는 니즈가 있으니까
아예 NVIDIA에서 모델 로드하고 GPU 최적화하고 아예 IaaS 같은 느낌으로 제공하는 듯.
GPT도 그렇고 허깅페이스도 Inference API 제공하고 있다고 함. 걍 여기다가 API 던지면 됨.
그럼 NIM의 차별성은? 사내 hosted API 라는데… 사내에 인플레이스 형태로 하는 것 같은데.
그러면 IaaS가 아니지 않남?
copilot - Scott
지금 copilot이 짜는 코드 보면 학생 개발자 수준인데
결국 AI는 사람 데이터를 통해서 학습하고 많은 수의 사람 데이터가 평범한 수준이니까
당분간은 평범한 사람 만큼만 기능하지 않을까?
결국 기업에서 선호하는 ‘잘하는 사람 수준의 AI’가 되려면 잘 하는 사람 데이터가 더 필요할 것 같고…
근데 AI가 만든 데이터를 바탕으로 결과를 잘 만들었는지 labeling하고 지도 학습을 좀 섞어주면,
그러면 사람을 능가 할 수도 있을거같은데…
이건 좀 오래걸리지 않을지.
LLM이 사람 대체 못하는 이유 RAG 인력이 필요하고, 시스템프롬프트를 짜는 사람이 필요하고, 모델 아웃풋을 검증하는 사람이 필요하다. 이런 인력들은 아직까지는 여전히 필요.
For now, it is impossible to let Copilot read multiple classes and use them.
However, it is important to understand the relationship between classes and files in software because modern enterprise applications are so complex that they consist of multiple classes.
Is there any plan to support the feature of generating code from multiple classes while understanding the whole application context?
And if so, how long does it take? This might be related to the capability of the model’s input.
⇒ 이거 질문을 copilot 부스에서 함.
부스 - copilot
Q. 지엽적인건 잘 동작하던데, 여러개 파일 인풋으로 넣어서 클래스 설계라던가… 이런거 해주지 못하는 것 같은데 계획 있냐
A. 일단 기본적으로 해당 커서가 위치한 파일과 그 주변의 파일을 읽어서 결과를 만드는 알고리즘이다.
원하는 file 들을 명시적으로 넣어서 그 컨텍스트에서 쓰는거 된다. fileName 명시해주면 된다.
근데 파일이 너무 많으면 다 못읽는다. 왜냐면 뒷단에서 다 GPT 쓰는거기 때문에 GPT 자체의 토큰 개수 한계가 있다. (8,192 tokens)
프롬프트 엔지니어링을 통해 OpenAI 모델과 상호 작용하는 방법 배우기
Basic-Prompting | Learn how to interact with OpenAI models
 전통적 AI 모델은 고비용 저효율, specific한 분야 별로 한 가지 분야에 특화된 AI 모델을 정의. 그러다 보니 비용도 많이 들고…
전통적 AI 모델은 고비용 저효율, specific한 분야 별로 한 가지 분야에 특화된 AI 모델을 정의. 그러다 보니 비용도 많이 들고…
⇒ Generative AI 나오면서는 Foundation model로 1개의 거대한 다용도 모델.
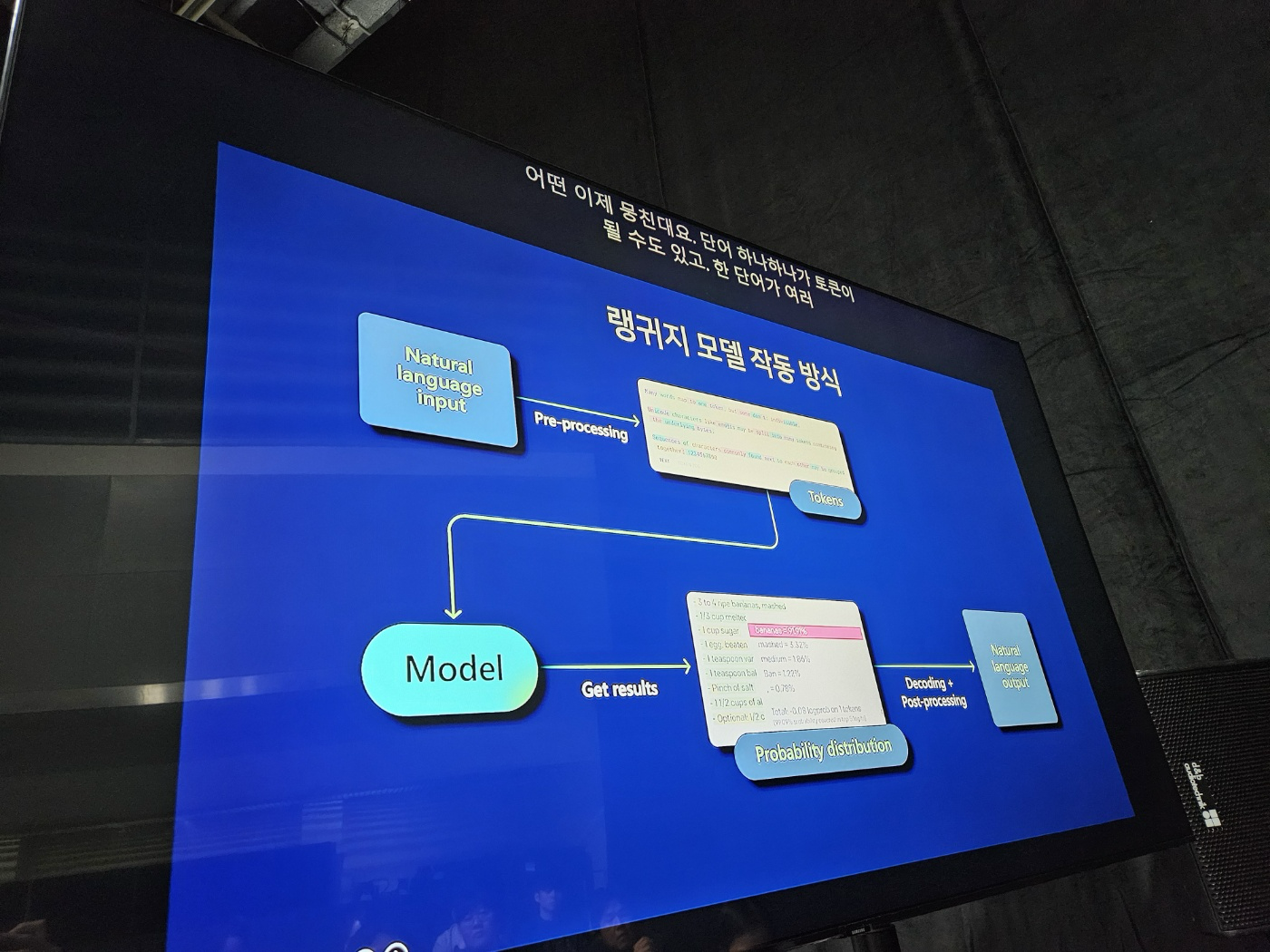
다음에는 어떤 토큰이 올까? 를 확률 분표를 이용해서 확률적으로 예측해서 토큰을 붙이고… 반복

프롬프트 엔지니어링이란?
⇒ NLP 기법 중 하나로, 입력 시 해야 할 일에 대한 설명을 포함하면서 원하는 결과를 출력하게끔 모델에 명령하는 것.
퓨샷 프롬프트
- 예시를 몇 개 주는 것. (반대는 제로샷 프롬프트)
컨텍스트 윈도우
모든 프롬프트와 컴플리션에서 토큰 공유을 공유.
프롬프트를 주고 응답을 받고… 지속하는 과정에서 history를 초기화하지 않는다면 이전에 보냈던 프롬프트를 다 한꺼번에 보낸다.
이 것도 한계가 있어서 context window에 해당하는 범위 내에 있는 history만 보낸다 ~ (token size에 달려있음)
앱 개발 시 요걸 항상 신경써서 개발 해야 한다.
top p값이 0.1이면, 상위 10%에 해당하는 토큰 중에서 아무거나 랜덤으로 하나 선택해서 붙여줘. 라는 의미.
⇒ 즉, top p 값을 얼마로 설정하느냐에 따라서 토큰을 얼마나 무작위로 붙일지가 결정됨.
temperature 매개변수는 모델이 얼마나 “창의적”으로 표현될 수 있는지를 제어합니다. “temperature”의 값이 낮으면 모델이 가장 높은 가중치를 가진 완성도로 응답할 가능성이 매우 높으므로 응답의 가변성이 제한됩니다. ‘temperature’의 값이 높을수록 가중치가 낮은 완성이 생성될 가능성이 높아져 보다 창의적인(그러나 정확도는 떨어지지만) 응답이 가능합니다.
⇒ 응답을 얼마나 결정적으로 만들 것인지를 결정.
fine-tuning vs RAG
파인튜닝이 예전에는 많이 했는데 새로운 지식을 추가하기 위해서는 그다지 좋지 않다. 가성비가 나쁘기 때문.
파인튜닝 한 결과를 또 믿을 수 있겠는가? 관점의 문제도 있다.
물론 필요하긴 하지만, 다른 대안 RAG 가 있기 때문에 ~
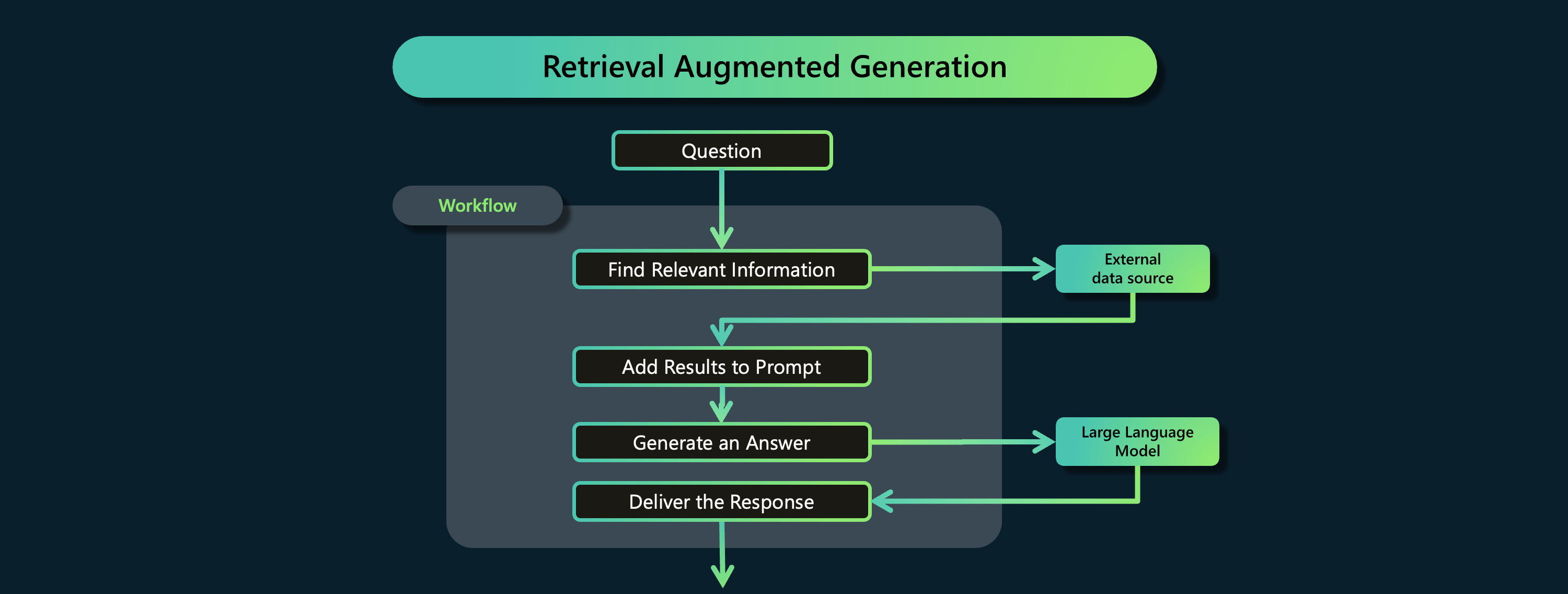
결국 (유저프롬프트 + 시스템프롬프트 + RAG 결과) ⇒ 모델 이렇게 들어간다.
LLM은 2번 쓰인다. 1. RAG에 넣기 전에 임베딩에 쓰이고, 2. 최종 결과에 쓰인다.