6장. 물리적 데이터베이스 설계 - 인덱스 기본 원리
디스크 상에서 화일의 레코드 배치
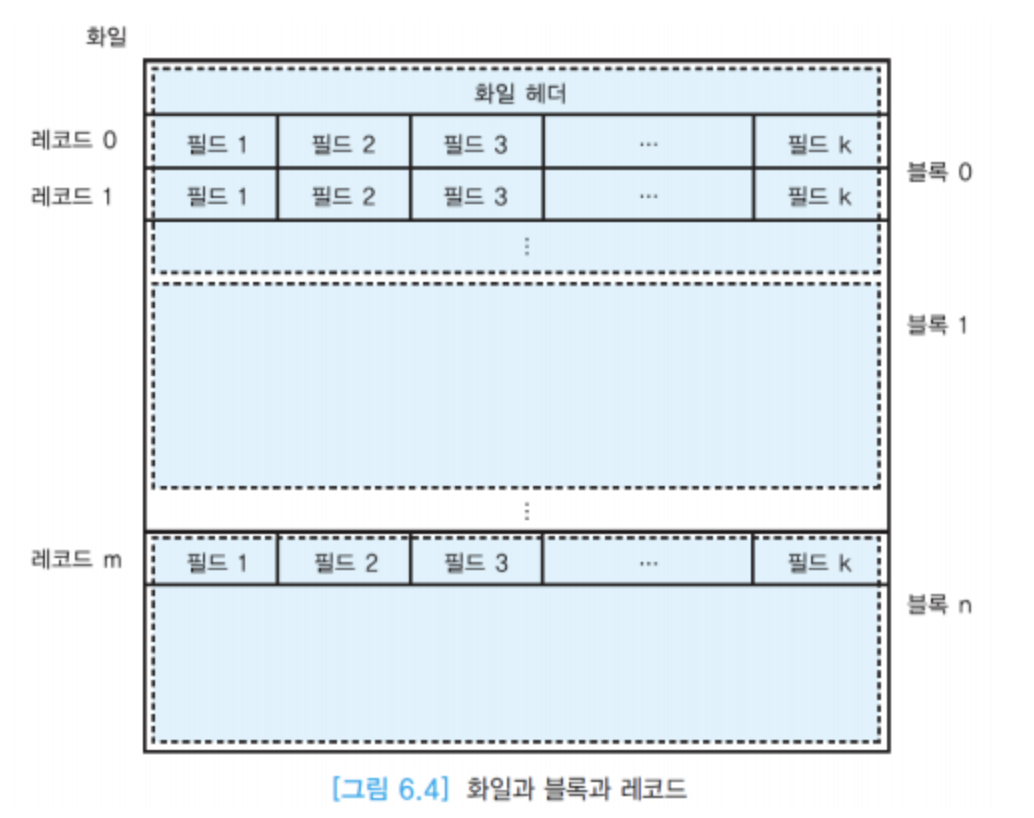
- 결국 DB에 저장되어 있는 레코드들도 최종적으로는 파일 안에 들어있다.
- [원하는 레코드가 위치한 블록을 어떻게 빨리 찾을 것인가?, 블록을 얼마나 적게 읽을 것인가?]가 핵심.
- Disk IO는 block 단위로 이루어지기 때문에 block을 몇 개 읽어야 하는지가 중요하다. (page 단위로 메모리에 올리게 되니까)
DBMS의 버퍼 관리
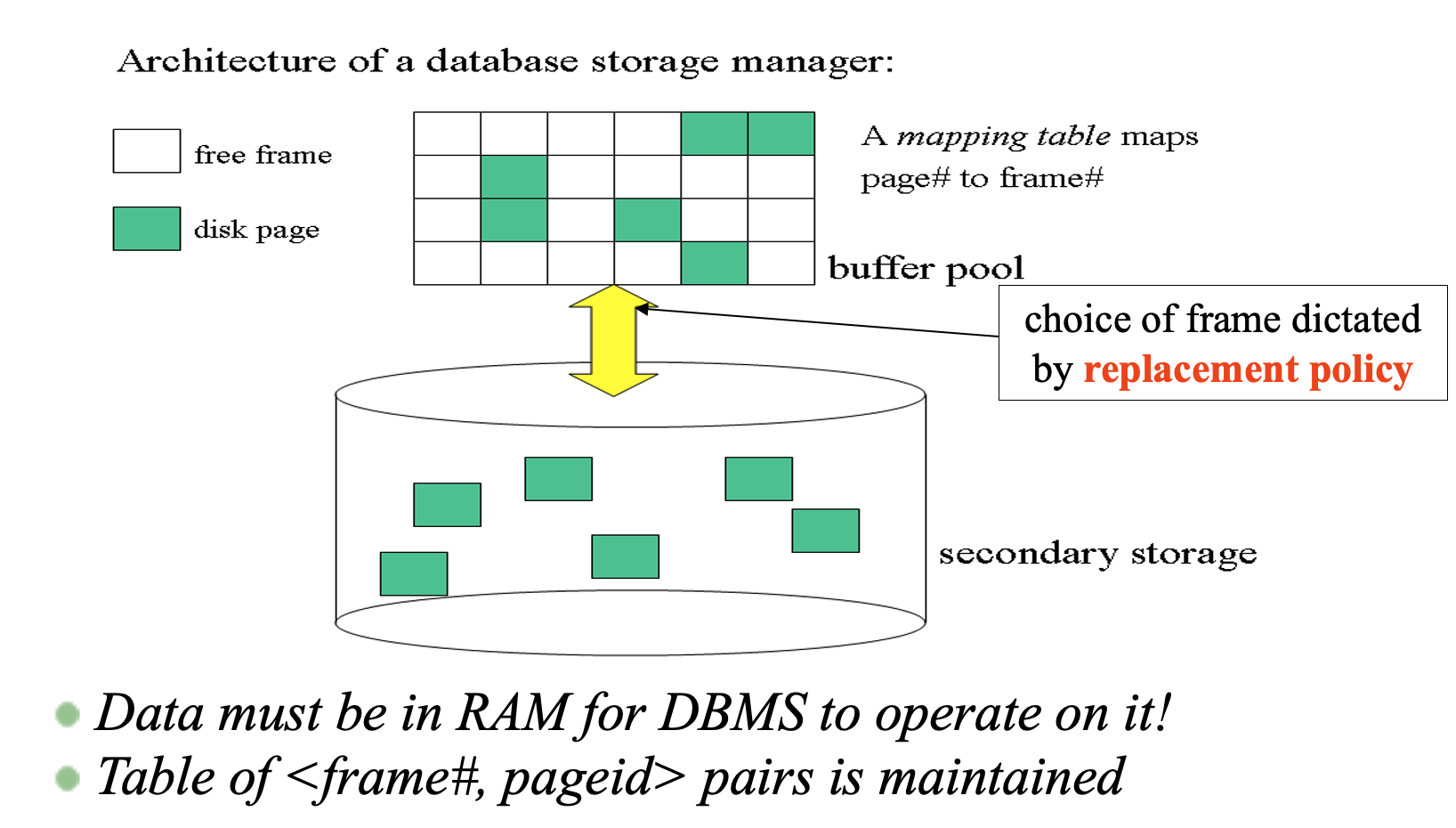
- 어차피 DB에 있는 레코드들도 다 디스크에 저장되어 있다가 메모리에 올라가야 서빙이 가능함.
- DBMS는 메모리에서 버퍼 영역을 따로 잡고 관리함.
다단계 인덱스
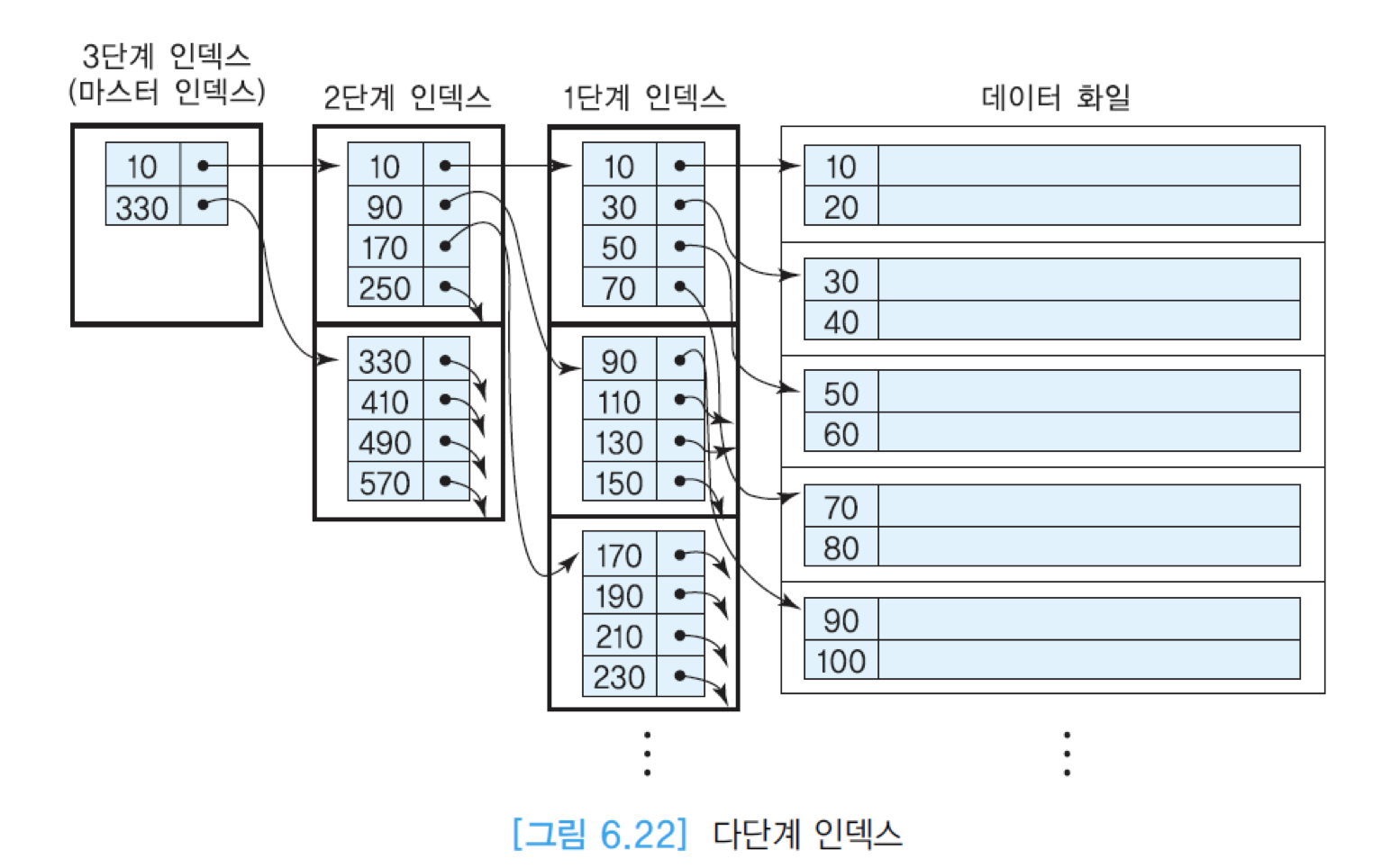
- 대부분의 다단계 인덱스는 B+ 트리를 사용
- 06장. 인덱스 구조 / 07장. 인덱스된 순차 화일 : B트리
클러스터링 인덱스 vs 비 클러스터링 인덱스
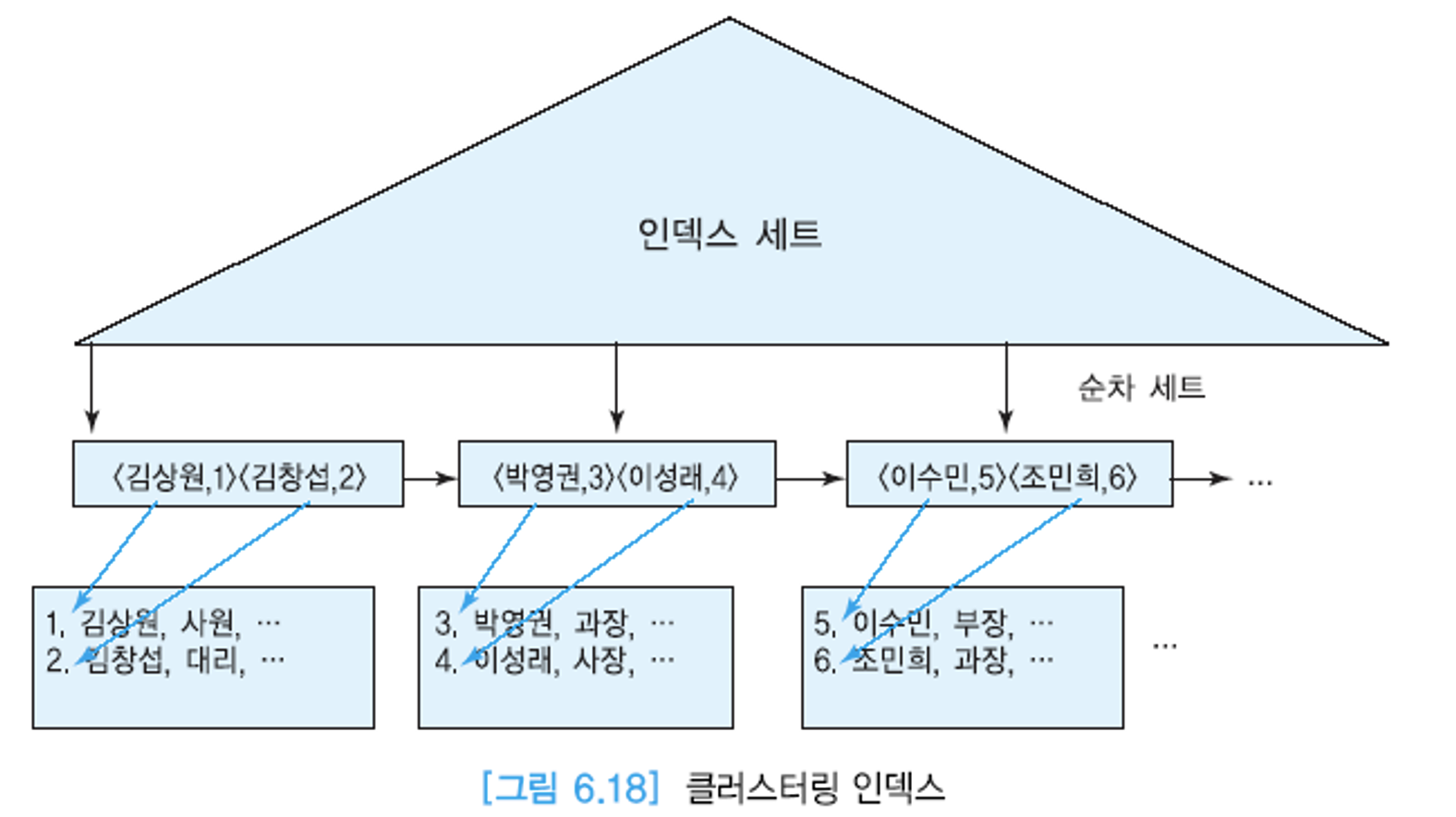
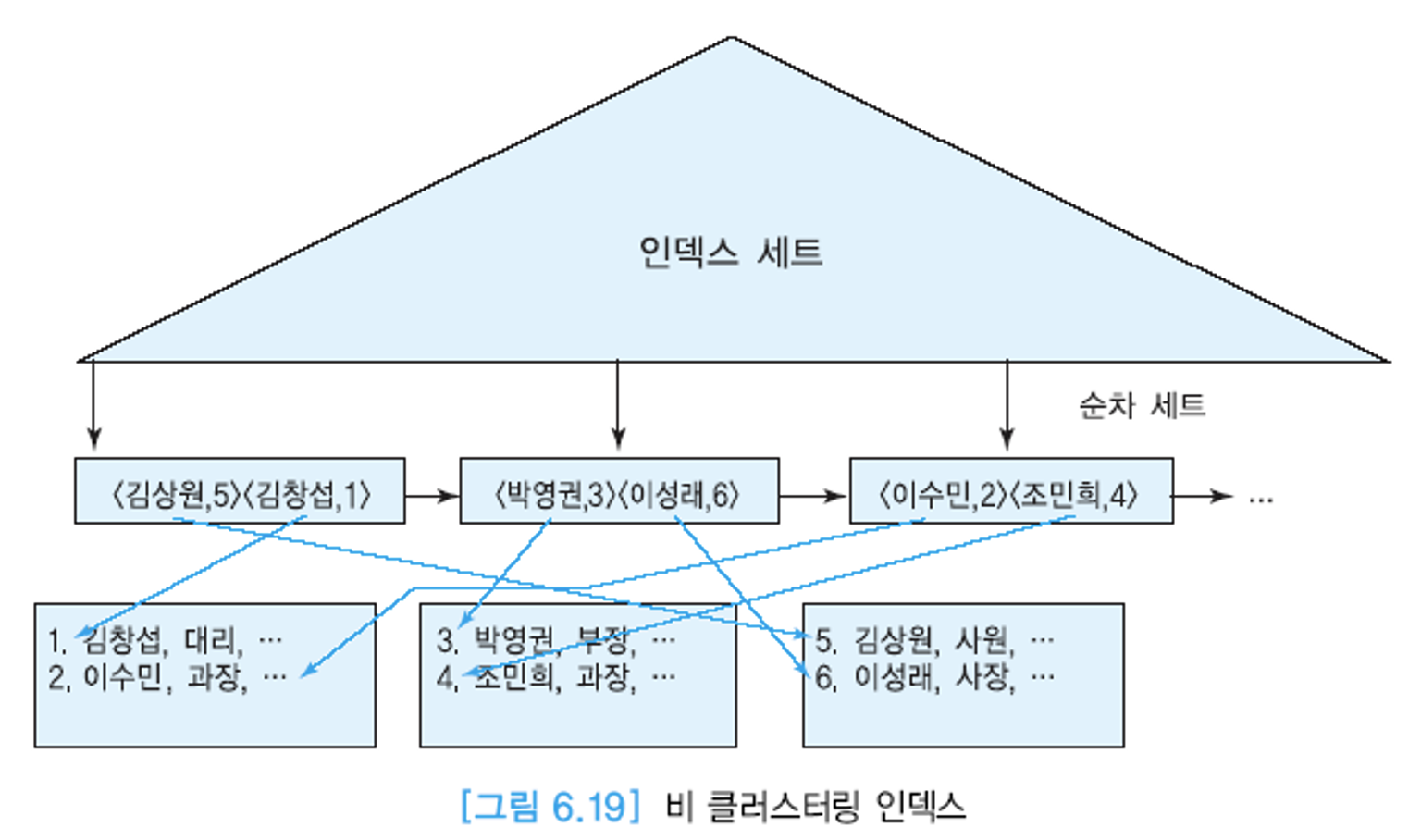
- 클러스터링 인덱스 (기본 인덱스)
- 인덱스 key의 정렬 순서와 실제 레코드의 정렬 순서가 일치하는 인덱스
- 하나의 파일은 물리적으로 하나의 정렬 기준만 가질 수 있기 때문에, 기본 인덱스(클러스터링 인덱스)는 최대 1개.
- 범위 질의에 유용. 어떤 인덱스 엔트리에서 참조되는 데이터 블록을 읽어오면 그 데이터 블록에 들어 있는 대부분의 레코드들은 범위를 만족함. (시퀀셜 액세스 )
- 비 클러스터링 인덱스 (보조 인덱스)
- 인덱스 key의 정렬 순서가 실제 레코드의 정렬 순서와 무관한 인덱스.
- 따라서 요구사항에 따라 추가 정의하게 되는 대부분의 인덱스는 비 클러스터링 인덱스.
- 이 경우 실제 레코드에 대한 접근은 랜덤 액세스가 된다. 1~100까지 찾는데 각각의 레코드가 서로 다른 block에 속해 있다면(최악의 경우) 100개의 block을 읽어야 한다.
- 여기서 랜덤은 정말 무작위로 접근한다는 의미가 아니라, 디스크 블록을 읽어오는 관점에서의 랜덤 액세스를 의미한다. 순차 접근이 아니라 디스크 헤드를 움직여 읽어야 한다는 의미.
- 순차 접근해야 유리하도록 설계되어 있는 디스크에서 Random Access하니까, 당연히 느리다.
- (RAM이 Random Access가 바로 가능하도록 설계 되어 있는 것과 달리 디스크는 Sequential Access 하도록 설계 되어 있다.)
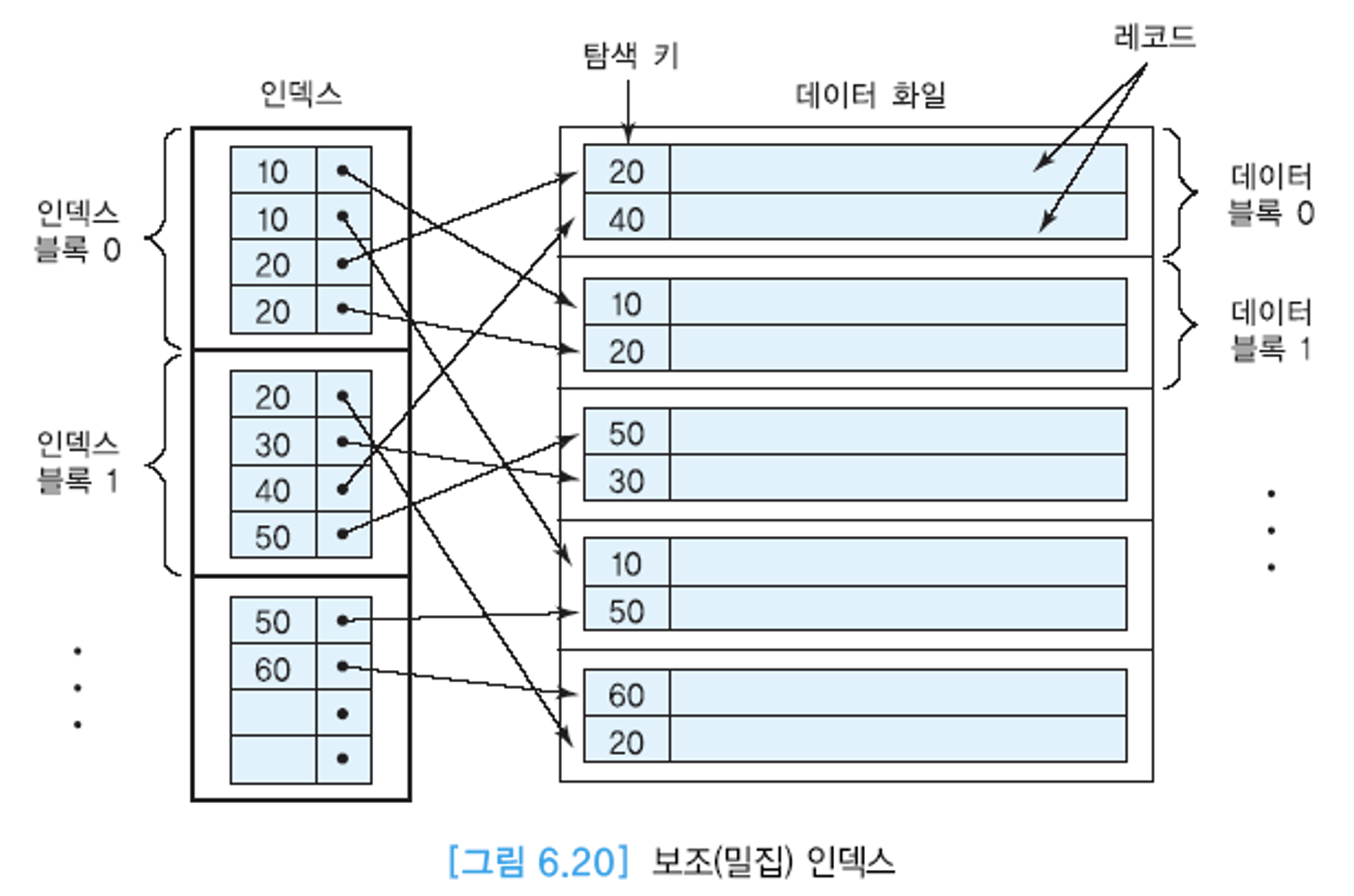
희소 인덱스 vs 밀집 인덱스
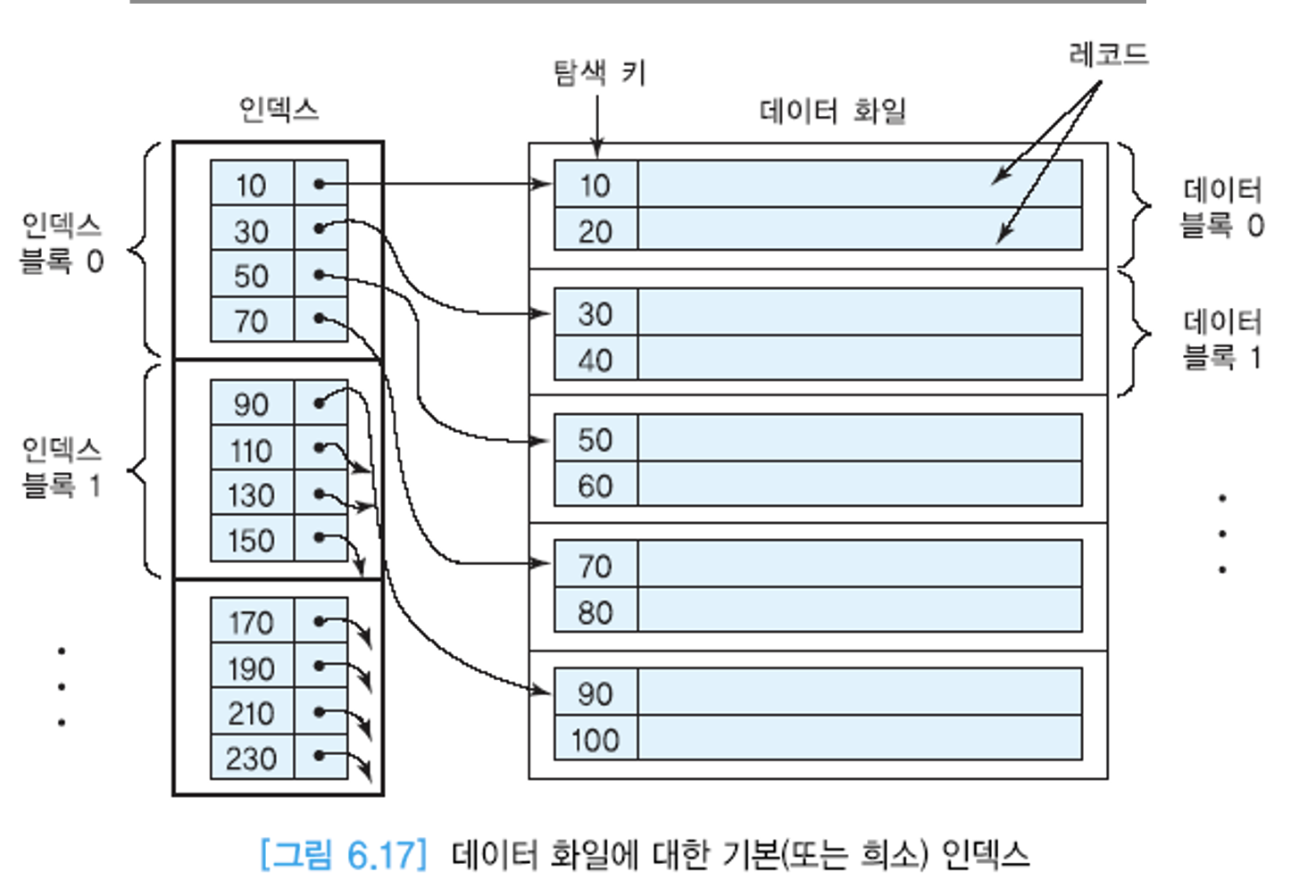
희소 인덱스
- 희소 인덱스는 블록 안의 레코드들이 인덱스 key로 정렬이 되어 있어야만 하므로(블록 첫번째 레코드 부터 쭉 탐색해야 하니까) 클러스터링 인덱스여야만 함.
- 밀집 인덱스
- 실제 레코드의 정렬과는 관계 없이 정의 가능하다. 클러스터링 인덱스 일 수도, 비클러스터링 인덱스 일 수도 있음.
- 한 화일은 한 개의 희소 인덱스(기본 인덱스)와 다수의 밀집 인덱스(보조 인덱스)를 가질 수 있음.
- 기본 인덱스는 클러스터링 인덱스이고, 클러스터링 인덱스는 희소 인덱스인 경우가 많음.
- 보조 인덱스는 비클러스터링 인덱스이면서 밀집 인덱스.
비교
- 희소 인덱스가 유리한 경우
- 레코드의 길이가 블록 크기보다 훨씬 작은 일반적인 경우에는 희소 인덱스의 엔트리 수가 밀집 인덱스의 엔트리 수보다 훨씬 적음
- 희소 인덱스는 일반적으로 밀집 인덱스에 비해 인덱스 단계 수가 1정도 적으므로 인덱스 탐색시 디스크 접근 수가 1만큼 적을 수 있음
- 밀집 인덱스가 유리한 경우
- 질의에서 인덱스가 정의된 애트리뷰트만 검색하는 경우에는 데이터 화일을 접근할 필요 없이 인덱스만 접근해서 질의를 수행할 수 있으므로 밀집 인덱스가 희소 인덱스보다 유리.
- 커버링 인덱스
- 쿼리 검색 결과 표현에 필요한 데이터를 레코드 참조 없이 인덱스만 봐도 모두 알 수 있는 경우
- 인덱스의 크기는 데이터 레코드의 크기에 비해 훨씬 작기 때문에, 한 block을 읽었을 때 가져올 수 있는 item의 수가 훨씬 많다. 따라서 데이터 레코드를 읽지 않고 바로 결과를 반환 할 수 있도록 커버링 인덱스를 생성 하는 경우가 있다.
복합 인덱스 (결합 인덱스) 구조
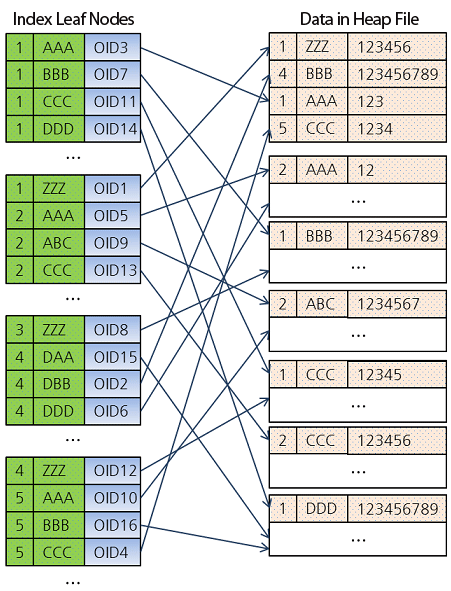
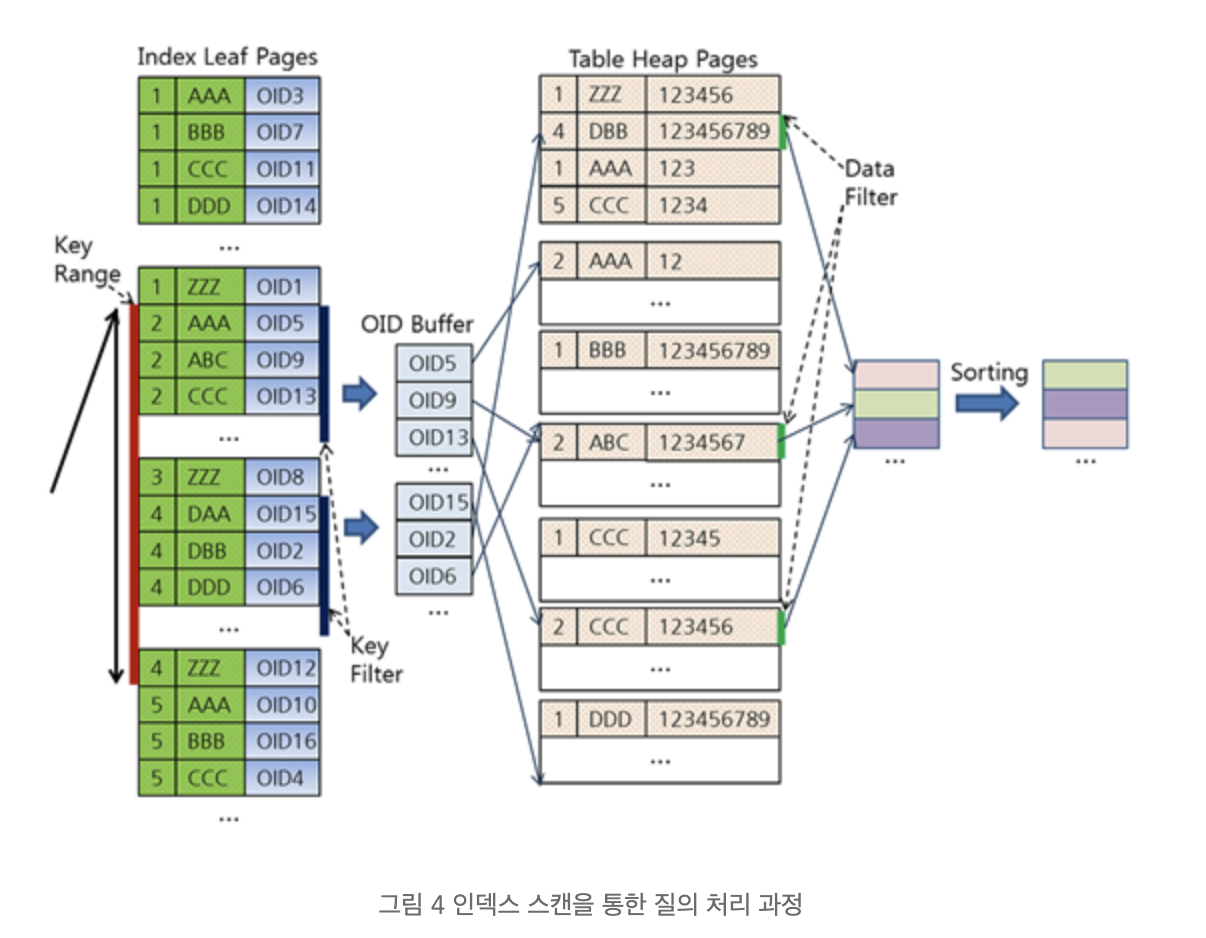 https://d2.naver.com/helloworld/1155
https://d2.naver.com/helloworld/1155
- 복합 인덱스 (a, b)이면, a 하위에 b가 정렬되어 있는 식이다.
- 위 그림 예제는 밀집 인덱스를 나타낸다.
- 밀집 인덱스이고, 커버링 인덱스를 타지 않는 경우에도 복합 인덱스는 의미가 있다.
- DB 속도 향상의 핵심은 disk IO를 줄이는 것이다. 이는 보통 데이터 블록 접근을 최소화 하는 것을 의미한다.
- b 컬럼을 알아내기 위해 데이터 블록에 접근해서 row를 가져온 후 필터링 하는 것 보다, 인덱스 블록만 가져와서 b 컬럼을 알아내어 필터링을 먼저 적용(Key Filter 부분)하고 데이터 블록에 접근하는 것이 속도에 훨씬 도움이 된다.
- 인덱스 블록은 데이터 블록 보다 크기가 현저히 작기 때문이다.
인덱스 기본 원리를 이해하는데 도움이 되는 글
- https://d2.naver.com/helloworld/1155 - CUBRID 성능 향상을 위한 SQL 작성법
- https://dataonair.or.kr/인덱스 기본 원리와 스캔 종류, 클러스터링 인덱스
- https://dataonair.or.kr/조인 수행 원리
- https://dataonair.or.kr/조인 기본 원리
실제로 인덱스를 생성 할 때 도움이 되는 글
This post is licensed under CC BY 4.0 by the author.