인덱스 관련 총정리
인덱스 관련 총정리
인덱스 관련 이론
- 6장. 물리적 데이터베이스 설계 : 인덱스 관련
- https://dataonair.or.kr/인덱스 기본 원리
- index range scan
- index full scan
- index unique scan
- index skip scan
- 등등 다양한 인덱스 스캔 방식과 인덱스 종류에 대한 설명
- https://d2.naver.com/helloworld/1155
- https://docs.oracle.com/cd/E11882_01/server.112/e40540/indexiot.htm#CNCPT721
옵티마이저가 query execution plan 세울 때 참고하는 것 : 통계
- 데이터베이스 옵티마이저는 쿼리 실행 계획을 세울 때 사용하는 가장 중요한 도구가 바로 ‘통계(Statistics)’ 정보
- 통계 정보란 테이블과 인덱스에 대한 일종의 ‘메타데이터’
- 테이블의 총 로우 수
- 컬럼의 유니크한 값 개수 (Number of Distinct Values, NDV)
- 컬럼 값의 분포도 (Histogram)
- 최솟값/최댓값 등
- 옵티마이저는 이 통계 정보를 보고 특정 조건(
WHERE a=10)이 얼마나 많은 데이터를 필터링할지 ‘예측’
커버링 인덱스 적용하기
커버링 인덱스는 SELECT의 모든 컬럼이 인덱스에 들어있어야 적용된다.
허나 그렇지 않다고 하더라도, Data Filter 보다 Key Filter를 적용하는게 성능에 큰 도움이 된다. Data Filter 이전에 Key Filter를 넣어주면…
- 데이터 레코드는 최종적으로 결과를 표현 할 때만 필요하기 때문에 데이터 레코드를 읽어와서 조건에 맞지 않으면 버리는 과정을 절약 할 수 있음.
- 인덱스의 크기는 데이터 레코드의 크기에 비해 훨씬 작기 때문에, 한 block을 읽었을 때 가져올 수 있는 item의 수가 훨씬 많다. 따라서 데이터 레코드를 읽고 filtering하는 것 보다, 인덱스 단계에서 filtering 하는 것이 읽어야 하는 block 수를 절약할 수 있어 더 낫다.
NDV, 선택도, 카디날리티
- NDV(Number of Distinct Value)
- 선택도(selectivity)
- 전체 레코드 중에서 조건절에 의해 선택될 것으로 예상되는 레코드의 비율(%)
- 인덱스 스캔이 테이블 순차 스캔보다 항상 빠르지는 않다. 보통 선택도(selectivity)가 5~10% 이내인 경우에 인덱스 스캔이 우수하다.
- 카디날리티(Cardinality)
- (선택도 * 총 row 수)
- 즉 해당 predicate로 선택된 row의 수. Optimizer가 plan 짤 때 참고하게 된다.
- 인덱스는 NDV가 높아야 의미가 있다. (e.g., 성별 같이 NDV가 2이면 인덱스 거는 의미가 없다.)
복합(결합) 인덱스에서 카디날리티 차이에 따른 쿼리 실행 퍼포먼스 차이
- https://jojoldu.tistory.com/243
- 이 분석글에서는 차이가 있는 것 처럼 보이지만, 실제로는 이 자체만으로는 큰 차이가 없는 것 같다. (-> 차이가 없는게 맞다)
- https://dba.stackexchange.com/questions/174227/cardinality-column-order-in-compound-index-mysql-innodb
- https://richardfoote.wordpress.com/2008/02/13/its-less-efficient-to-have-low-cardinality-leading-columns-in-an-index-right/
- A common myth or mis-perception is that when deciding how to order the columns in a concatenated, multi-column index, one should avoid placing low cardinality columns in front.
- 즉, 쿼리 조건이 모두 = 동등비교로 인덱스를 타는 경우라면, 인덱스가 어떤 순서로 구성되어 있든 블록IO 개수는 똑같다! 따라서 성능도 같다. (다른 원인으로 미미한 차이가 있을 수 있겠지만 결국 쿼리 성능을 좌우하는 main factor는 몇개의 블록IO가 발생하느냐 이다)
- 다만
=동등비교가 아니라 범위<, >, BETWEEN질의라면 얘기가 크게 달라진다.
범위 질의에서 복합 인덱스는 어떻게 되나?
1
2
3
4
5
SELECT * FROM tbl
WHERE a > 1 AND a < 5
AND b < 'K'
AND c > 10000
ORDER BY b;
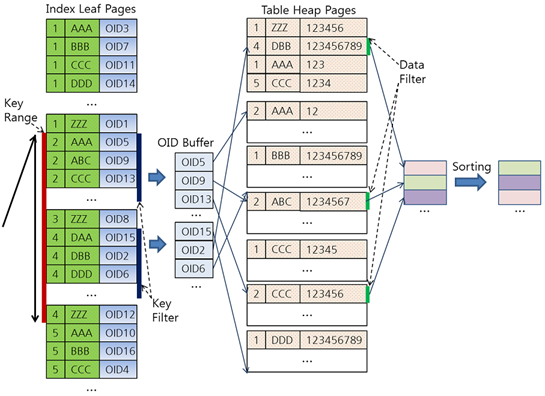 https://d2.naver.com/helloworld/1155 - CUBRID에 대한 설명이지만 대부분의 RDB가 비슷할 것이다.
https://d2.naver.com/helloworld/1155 - CUBRID에 대한 설명이지만 대부분의 RDB가 비슷할 것이다.
- (1, 2, 3 …)은 첫번째 컬럼인 a이고, (AAA, BBB, CCC…) 는 두 번째 컬럼인 b이다. 초록색이 복합 인덱스 (a, b)를 의미한다.
- Key Range: 인덱스 스캔 범위로 활용하는 조건이다(a > 1 AND a < 5).
- Key Filter: Key Range에 포함할 수 없지만 인덱스 키로 처리 가능한 조건이다(b < ‘K’).
- Data Filter: 인덱스를 사용할 수 없는 조건이다. 테이블에서 레코드를 읽어야만 처리 가능한 조건이다(c > 10000).
- 즉… 인덱스의 선두 컬럼 a가 범위 질의이면, 컬럼 a의 범위에 해당하는 인덱스 블록을 일단 모두 읽어들인 후, 인덱스 블록 데이터에 포함된 인덱스 컬럼 b를 기준으로 filtering해서 조건에 맞지 않는 항목들을 버리는 식으로 동작한다.
- a, b를 동시에 만족하는 인덱스 블록들만을 한번에 찾아가서 읽어들이는 것이 아니다!
- 왜 이런 구조일까? 여기까진 잘 모르겠다.
- 1<a<5 AND b=’DDD’ 조건일 때, 상위 인덱스가 [(2, AAA), (2, KKK), (3, AAA)…] 수준으로 나뉘어져 있다면 인덱스 블록 탐색 범위를 반으로는 줄일 수 있을 것 같은데… [(2, AAA), (3, AAA)…]만 읽으면 되니까.
- 실제로 돌려보면 이렇게 인덱스를 검색해서 탐색하는 것 보다, 일단 a를 기준으로만 다 읽고 filtering 하는 방식이 더 빠르기 때문일까? 아니면 인덱스가 너무 세밀해서 trade-off가 발생하기 때문일까? 여기까진 잘 모르겠다.
- a의 범위가 커도 충분히 빠를까? => 그렇지 않다.
- 컬럼 a가 시간이고, 컬럼 b가 userId라고 가정해보자. 하루치 데이터는 200만건이다. 인덱스 (a, b)는 보조인덱스다.
- 특정 유저의 1일치 데이터를 가져오려면, 2023-08-01<a<2023-08-02 AND b=’userId’
- Key Range: 일단 1일치에 해당하는 인덱스 블록을 모조리 가져온다. (보조인덱스 이므로 200만건)
- Key Filter: 200만건을 b=’userId’로 filtering 한다.
- 본질적으로 200만건에 대한 필터링이므로, b=’userId’인 row가 1만건이어도 a의 범위가 크면 클 수록 느려진다. (실제로 성능 좋은 Oracle에서 돌려보니 5s 걸렸다)
- a의 범위가 큰데, 인덱스 순서를 (b, a)로 바꾸면?
- 위와 동일한 상황에서 인덱스 순서를 (b, a)로 바꾸게 되면
- Key Range: b=’userId’에 해당하는 인덱스 블록 가져온다. (보조인덱스 이므로 1만건)
- Key Filter: 1만건을 2023-08-01<a<2023-08-02로 flitering 한다.
- 즉 범위 질의 하는 경우 NDV에 따른 복합 인덱스의 순서가 매우 중요해진다.
[!info] 이처럼 복합인덱스의 동작과 성능을 이해하기 위해서는 key range와 key filter의 차이를 반드시 알고 있어야 한다.
This post is licensed under CC BY 4.0 by the author.